
Сегодня мы поговорим об очередной интересной технологии — VxLAN — что это за зверь и с чем его едят, да и вообще нужен ли он вам. Мое знакомство с данной технологией началось с изучения гипервизоров — я постоянно натыкался на термин VxLAN, но что это и как работает не знал. В один прекрасный день я решил все-таки прочитать, что это за зверь. Прочитав пару-тройку статей, я усвоил для себя основные аспекты работы технологии и облегченно выдохнул, прочитав, что данная технология — удел гипервизоров и к транспорту имеет косвенное отношение (хотя, как оказалось позже отношение VxLAN к транспорту имеет самое, что ни на есть прямое). После чего про технологию благополучно забыл и вернулся я к ней снова только через год, когда начал погружаться в EVPN — большинство статей и мануалов были именно о симбиозе EVPN и VxLAN. Литературы по данной технологии много, особенно если вы владеете английским. Я же попробую в данной статье рассказать об основах работы данной технологии и показать на практике — как это настраивается и работает. Но начнем с MPLS…
Для меня, как инженера, который эксплуатирует сеть IP/MPLS самым важным в данной технологии являются ее возможности по организации виртуальных сетей 2-го и 3-го уровня (L2CKT, VPLS, L3VPN, 6PE и т д). Всякие трафик инжиниринги и фастрероуты, хотя и дают инженеру очень большие возможности в части управления трафиком и увеличивают количество 9-ок после запятой (теоретически — практически же все приводит к усложнению архитектуры сети и как следствие к увеличению срока решения аварий), но по сути не являются самоцелью развертывания IP/MPLS сети. Стал бы mpls такой популярной технологией и стандартом де-факто для больших, да и для небольших провайдеров, если бы не умел делать VPN-ы? Естественно нет. Ну согласитесь вряд ли вы стали бы перекраивать свою сеть ради внедрения трафик инжиниринга.
IP/MPLS сети как правило строятся на высокопроизводительных маршрутизаторах, например, Juniper MX или Cisco ASR9K/99 (во всяком случае ядро IP/MPLS сети). Для датацентра же такое оборудование как правило не типично, и обычно, если в датацентре установлены маршрутизаторы такого уровня, то они выполняют роль каких-нибудь PE-шек или бордеров, через которые организуются DCI-и или аплинки. Дело по большей степени в стоимости оборудования — стоимость одного порта на коммутаторе на много ниже чем стоимость аналогичного порта на маршрутизаторе (со схожими показателями пропускной способности, плотности портов на слот и т д). В датацентрах обычно установлены высокопроизводительные неблокируемые или частично неблокируемые коммутаторы имеющие высокую плотность портов емкостью 1/10/40/100G (в зависимости от типа оборудования ToR/EoR/Spine/Leaf), например, Cisco Nexus, весьма недурные изделия Аристы или Джунипера.
Но тот же Cisco Nexus 9K не пригоден для использования в MPLS домене, так как просто не имеет поддержки протоколов распредления меток, или, например, Juniper QFX, который MPLS вроде и поддерживает, но все-таки имеет ограничения, например, по размеру fib. То есть по сути запустить MPLS в датацентре, построенном на Juniper QFX теоретически возможно, но практически это будет не самое лучшее решение — в какой-то момент вы упретесь в возможности данного оборудования (причем этот момент наступит очень скоро).
С другой стороны, в датацентрах очень много систем, которые хотят иметь одновременно и L2 связность и георезерв. Как обеспечить L2 связность между серверами, расположенными в разных частях сети, не имея MPLS? В общем то, если покопаться, то существуют несколько различных вариантов решения данной проблемы. Мы же, как нетрудно догадаться из названия статьи, поговорим о специально заточенной под данные нужды технологии — VxLAN, которая позволяет строить географически растянутые L2 сети поверх обычной IP сети и на сегодняшний день является стандартом де-факто для датацентров.
Любой сервис, организуемый поверх IP/MPLS сети является туннелированием в том или ином виде — в любом случае мы что то через что то туннелируем. К примеру, возьмем простой L3VPN между точкой А и В. В самом простом варианте, без всяких опций C или Detour/Bypass тоннелей, мы имеем стек из двух меток — нижняя, сервисная метка и верхняя, транспортная. Естественно, что бы какой-то сервис между точками А и Б поместить в тоннель, нам нужен непосредственно сам end-to-end тоннель между этими самыми точками А и В. В качестве такого тоннеля в IP/MPLS выступает LDP/RSVP-TE LSP. Далее нам никто не запрещает внутрь этого транспортного тоннеля поместить еще один тоннель, который предназначен для форвардинга клиентского трафика.
В итоге мы получаем тоннель, который туннелируется через другой тоннель. То есть в конечном счете получается, что одна сеть (сеть клиента) строится поверх другой сети (сети провайдера). Сеть провайдера называется underlay сетью. По сути это фундамент для построения наложенных сетей — VPN-ов. Развёрнутые поверх underlay сети клиентские сети являются overlay сетями и строятся по какой то из существующих overlay-ых технологии — например все тот же L3VPN. То есть в VPLS/L2CKT/L3VPN и т д используется IP/MPLS сеть как underlay и тот же MPLS как overlay.
Но как быть, если у нас нет MPLS, а нам нужен L2VPN (если быть точнее то VPLS)? Как я и сказал ранее — существуют различные технологии, которые позволяют это сделать, мы же остановимся VxLAN. Данная технология, совместно с UDP, может организовать виртуальную L2 multipoint сеть (по сути аналог VPLS) без использования MPLS меток поверх какой-либо IP сети (может работать и поверх IP/MPLS сети – далее вы увидите, что технологии важна только IP связность). Сразу возникает куча вопросов, например, что выполняет роль тоннеля в underlay или что используется как сервисная метка в overlay? На эти и некоторые другие вопросы мы ответим дальше.
Итак, VxLAN это виртуальная расширенная частная сеть (Virtual eXtensible Local Area Network). В литературе вы можете встретить и другое название MAC-in-UDP. Это все тот же VxLAN, причем второе название намного лучше описывает суть технологии. Как вы догадались, VxLAN это технология, которая позволяет обычные ethernet кадры упаковывать в UDP сегменты и транспортировать их в таком виде по IP сети. Думаю, пока что мало что понятно, поэтому давайте подробнее.
В сети IP/MPLS маршрутизаторы, как правило, имеют какое-то определенное назначение — ну к примеру PE, P или ASBR. Маршрутизаторы уровня PE являются мультисервисными узлами агрегации. Говоря простым языком — это узлы, к которым подключены клиентские сервисы — именно на этих узлах берут свое начало и заканчиваются L2/3VPN-ы, VPLS-ы и другие VPN-сервисы, реализуемые поверх IP/MPLS сети (коммутаторы последней мили и всякие опции A/B/C мы сейчас не рассматриваем). Вторым важным элементом IP/MPLS сети являются маршрутизаторы уровня Р — по сути просто молотилки трафика (особенно если у вас Free Core), которые даже не догадываются, что они участвуют в организации каких либо VPN сервисов.
В технологии VxLAN тоже есть такие узлы, только называются они несколько иначе, хотя выполняют по сути те же самые функции. Аналогом PE маршрутизатора является VTEP — Vitual Tunnel End Point. Именно VTEP является узлом агрегации сервисов, причем VTEP-ом может быть не только ToR/EoR/Leaf коммутатор или PE маршрутизатор, но и обычный сервер, при наличии на нем необходимого софта ( к примеру, VMWare это умеет). Как и в IP/MPLS, на VTEP начинаются и заканчиваются VxLAN тоннели. Аналогом маршрутизатора уровня Р являются маршрутизаторы/коммутаторы, которые не терминируют клиентов и просто форвардят IP трафик — данные коммутаторы как правило даже не знают о существовании в сети VxLAN тоннелей (если на них не вынесли, например, шлюзы).
Объяснять что то на примере всегда проще, поэтому, прежде чем переходить к основным принципам работы VxLAN, вспомним другую очень важную и всем нам хорошо известную технологию — VLAN.
VLAN — это технология, предназначенная для сегментации сети на втором уровне. Как мы все знаем, стандартный коммутатор производит форвардинг фреймов на основании имеющейся (построенной им самим в процессе работы) таблицы форвардинга, в которой учитывается не только mac адрес назначения фрейма, но и его влан тег. Если провести аналогию VLAN с VRF, то каждый влан проще всего рассматривать как отдельную виртуальную сущность — то есть виртуальный коммутатор. Давая команду vlan 100 на Cisco, мы создаем виртуальный коммутатор с влан тегом 100. У каждого созданного нами виртуального коммутатора есть какой-то набор интерфейсов (разрешая влан на каком-то интерфейсе мы добавляем порт в определенный виртуальный коммутатор), а также таблица соответствия mac адресов и портов (ее мы смотрим командой show mac-address-table dynamic vlan 100).
Теоретически мы можем представить, что когда в какой-то порт коммутатора прилетает фрейм с влан тегом, то решение о дальнейшей отправке фрейма принимается на основании таблицы mac адресов соответствующего виртуального коммутатора. Если получен фрейм с тегом 100, то соответственно приниматься решение о форвардинге данного фрейма будет на основании mac таблицы виртуального коммутатора с тегом 100.
Классический коммутатор при получении какого-то фрейма (нам не важно какой это фрейм — бродкатный или юникастный) флудит его во все свои порты. Если же у коммутатора есть причина не флудить пакет в какой-то порт или группу портов — он этого делать не будет: если коммутатор точно знает, неважно откуда, что mac назначения не находится за определенным портом или же что данный фрейм отправлять в определенный порт или порты не надо (ну, например, включен igmp-snooping), то и флудить фрейм в этот порт (или порты) коммутатор не будет. Логично, что при получении какого-то фрейма у коммутатора есть как минимум причина не флудить этот фрейм обратно в порт, из которого он пришел — это банальное правило расщепления горизонта. Если коммутатор точно знает, что mac адрес назначения живет за определенным портом — фрейм будет отправлен только в один конкретный порт. Исходя из вышесказанного, логически коммутатор можно представить в таком виде:
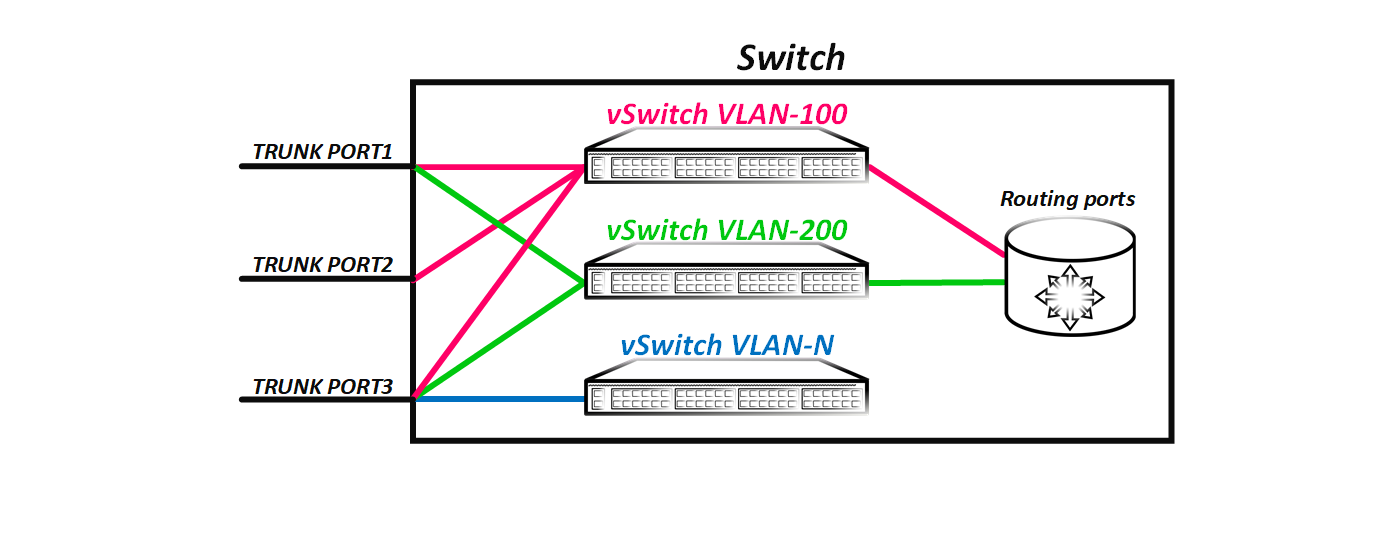
Как видим из картинки, получается, что фрейм, пришедший с влан тегом 100 попадает в виртуальный коммутатор 100 и логично, что теперь он не может просто так попасть в другой виртуальный коммутатор — то есть в другой влан, ну, например, 200, так как между виртуальными коммутаторами нет прямой связности. Когда же мы создаем роутинговый интерфейс, мы создаем интерфейс, через который виртуальный коммутатор может общаться с остальными виртуальными коммутаторами, у которых тоже есть роутинговый интерфейс — то есть производить роутинг пакетов между вланами.
На схеме показано, что у виртуальных коммутаторов VLAN-100 и VLAN-200 есть роутинговые интерфейсы, через которые данные виртуальные коммутаторы могу общаться. В тоже время у виртуального коммутатора VLAN-N не сконфигурен L3 интерфейс — то есть данный виртуальный коммутатор не имеет возможности общаться с другими виртуальными коммутаторами (в нашем случае с VLAN-100 и VLAN-200). Номер влана в классической L2 сети является глобальным — если у нас есть L2 домен из, например, 10-ти коммутаторов, то номера вланов являются глобальными для всего домена.
Но надо понимать, что это всего лишь упрошенная логическая модель коммутатора для понимания принципа его работы. И хотя влан можно представить, как виртуальный коммутатор, он в реальности же таковым не является. То есть у нас нет отдельной таблицы коммутации для влана 100 или для влана 200. Естественно мы можем посмотреть, какие маки мы изучили в каком-то определенном влане (причем вы можете увидеть, что один и тот же мак может быть в разных вланах), но это не говорит о том, что под данный влан на оборудовании выделена отдельная таблица. Коммутатор имеет одну единую таблицу форвардинга вне зависимости от количества сконфигуренных на нем вланов. Просто, когда происходит флудинг полученного фрейма, коммутатор знает, что данный фрейм отправлять в определенные порты не надо. Например, если порт eth1/1 является аксессным портом во влане 200 а порт eth1/2 является транковым портом, но на нем влан 100 не разрешен, то коммутатор (имеется ввиду физический) в эти порты фрейм с тегом 100 флудить не будет, так как точно знает, что за данными портами нет хостов в 100-м влане. Физически это происходит именно так, а вот логически проще представить, что данные порты не принадлежат виртуальному коммутатору с вланом 100 и поэтому в них фрейм просто не может быть отправлен.
Примечание: Не стоит пытаться применить данную концепцию к бридж-доменам на современных маршрутизаторах — это по сути другой мир со своими законами, в котором номер влана по сути имеет значение только на линке. Все описанное соответствует имеено классическому коммутатору, который не поддерживает расширенное пространство вланов. Про бридж-домены я писал отдельную статью (применительно к JunOS). Если кому-то интересно, то могу сделать аналогичную статью для IOX-XR.
То есть мы имеем следующее: у нас есть виртуальный коммутатор, определяемый каким-то vlan тегом и имеющий какой-то набор портов. Точно такая же концепция лежит в основе VxLAN. Только в VxLAN роль влан-тега играет VxLAN Network Identifier (иногда его называют и Virtual Network Identifier) или сокращённо VNI. В отличии от vlan-тега, длинна которого 12 бит (то есть в одном L2 домене может быть максимум 4096 вланов), VNI имеет длину 24 бита — то есть может принимать 16 777 214 уникальных значений. Как и vlan тег, VNI является уникальным для всего VxLAN домена. То есть если хост А живет за VTEP-ом А, а хост В за VTEP-ом В, то на обоих VTEP-ах эти хосты должны быть за интерфейсом, который относится к одному и тому же VNI, иначе L2 связности между хостами А и В не будет. Все аналогично VLAN — ведь если на одном коммутаторе хост будет во влане 100 а на соседнем другой хост во влане 200 — то L2 связности между данными хостами не будет.
Примечание: очень важно понять, что в отличии от MPLS метки, которая уникальна только в пределах одного узла, идентификатор VNI имеет глобальное значение для всего VxLAN домена. Поэтому посчитать, чего будет больше L2 сетей при использовании VxLAN или VPLS (с MPLS) очень сложно. Абсолютное значение естественно и указывает в пользу VxLAN. Но если в VPLS вы можете использовать одну и ту же метку для разных клиентов (например, если VPLS домен 1 на PE 1 будет использовать метку 299001, это не значит, что VPLS домен 2 на PE 2 не может использовать ту же самую метку 299001). А вот при использовании VxLAN такой номер не пройдёт. Если использовать один и тот же VNI и на PE1 и на PE2, то тогда клиент, подключенный к PE1, сможет общаться с клиентом, подключенным к PE2.
Как я написал ранее — при создании влана мы по сути создаем виртуальный свич и далее добавляем в него какие то порты и роутинговый интерфейс (при необходимости). Но какие порты мы добавляем? Обязательно ли нам использовать физические порты? Или можно воспользоваться виртуальными? Вспомним, например, такой протокол как GRE. При создании GRE тоннеля создаётся логический интерфейс — например gre-0/0/0 в JunOS. Точно так же и при создании VxLAN тоннеля — на коммутаторе появляется туннельный интерфейс, например, vtep.xxx в JunOS. Данный интерфейс, как мы увидим далее является транковым и способен переносить как тегированные, так и не тегированные фреймы. Если у вас есть возможность залезать на какую-нибудь коробку и посмотреть таблицу мак адресов в VPLS, то вы увидите, что часть маков будет видна не через физический порт, а логический lsi интерфейс (на примере JunOS). Lsi-интерфейс и есть не что иное, как тоннель (псевдопровод в терминах VPLS) до какого либо PE маршрутизатора. Чем хуже VxLAN тоннель? В VxLAN использует такой же принцип — только сигнализация тоннелей другая.
В итоге получается, что коммутатор использует имеющиеся у него VxLAN тоннели как транковые порты, в которые, так же как и в реальный порт, флудятся пакеты и через него изучает маки. То есть если у нас несколько удаленных VTEP-ов, то логическая схема свича будет теперь иметь такой вид:
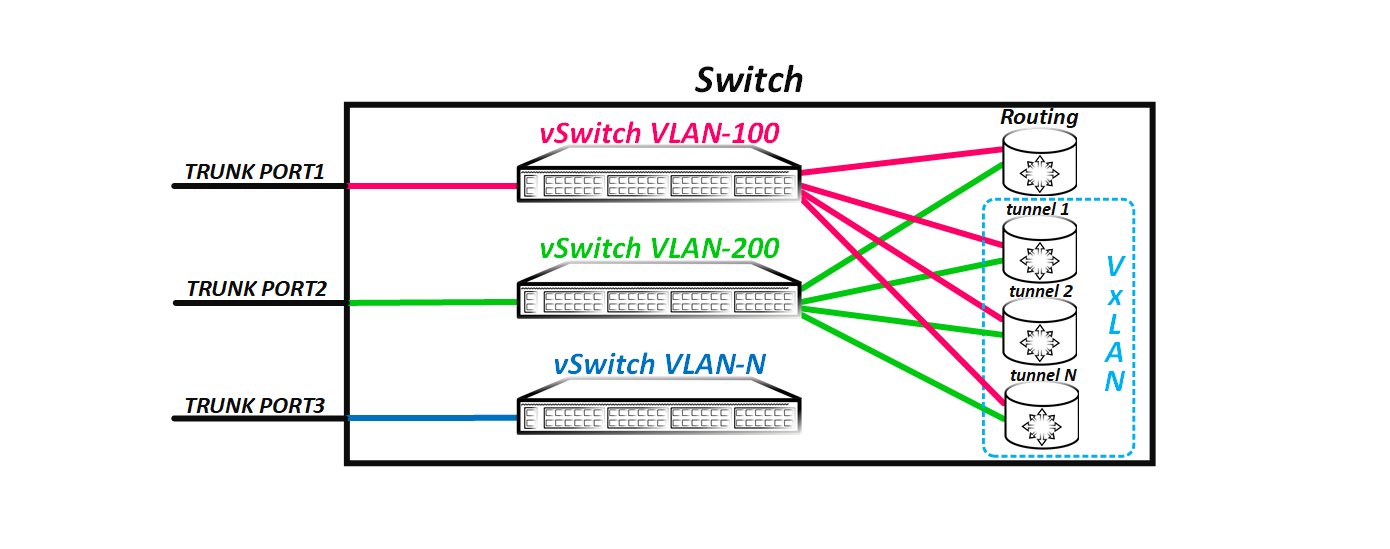
Но как я говорил в начале, если у порта есть причина не флудить полученный кадр в какой-либо порт или группу портов — то он не будет этого делать. По умолчанию фрейм не отправляется только в порт, из которого он прилетел — это простое правило расщепления горизонта. В VxLAN данное правило тоже работает, только есть некоторые нюансы.
Предположим, что фрейм получен через физический порт. В таком сценарии все нормально — коммутатор просто флудит пакет во все порты (ну кроме порта, откуда получен фрейм). Но что, если фрейм получен через VxLAN тоннель? Так как между всеми VTEP-ми создается полносвязанная топология из VxLAN тоннелей, то логично, что полученный из тоннеля фрейм не надо снова флудить в другие VxLAN тоннели, так как остальные VTEP-ы уже получили этот фрейм — в этом же и есть суть полносвязной топологии.
Но как понять, при каких обстоятельствах в какие порты надо флудить фрейм, а в какие не надо? Для этого порты, которые являются VxLAN тоннелями, объединены в виртуальную группу (назовем ее split horizon group) и если фрейм получен из какого-то порта, являющегося членом данной группы, то в остальные порты, входящие в данную группу, фрейм флудиться не будет. Естественно, оборудование позволяет вам изменить это поведение, например, для hub-and-spoke топологии. Но просто так это делать не стоит — широковещательный шторм «веселая» штука.
Подытожим первую часть нашей статьи: VxLAN является расширенным аналогом VLAN — то есть является виртуальной L2 сетью. Виртуальные L2 сети разделены между собой и трафик между этими сетями коммутироваться не может — для этого нужна маршрутизация. Подобно VLAN, VxLAN имеет аналог VLAN тега, который служит идентификатором виртуальной L2 сети — VxALN Network Identifier (VNI). Длинна VNI равна 24 битам, что позволяет использовать более 16 миллионов виртуальных L2 сетей в одном домене. Как и VLAN тег, VNI является глобально уникальным для всего L2 (VxLAN) домена. Изучение mac адресов производится методом flood-and-learn — коммутатор флудит фрейм во все порты (в какие порты не флудится и почему мы разобрали ранее) и по source mac адресу заполняет таблицу форвардинга. Далее мы поговорим о том, как происходит поиск удаленных VTEP-ов и сигнализация тоннелей.
Итак, как я написал в начале статьи — vpn это туннелирование чего-то через что-то. В IP/MPLS как underlay используется IP/MPLS сеть, и тот же MPLS как overlay. Это не единственные технологии, которые позволяют через себя что-то туннелировать. Вернемся снова к протоколу GRE. Это overlay-я технология, которая создает виртуальный p2p линк между точками А и В. Данный протокол инкапсулирует оригинальному IP пакет в новый IP пакет, вставляя между этими заголовками свой собственный GRE заголовок.
VxLAN все несколько сложнее, но этому есть объяснение. Как и в GRE, к оригинальный ethernet кадру добавляется VxLAN заголовок. Данный заголовок имеет длину 8 байт и кроме флагов и зарезервированных полей несет в себе описанный ранее VNI. То есть, как вы понимаете данный заголовок необходим, что бы на удаленной стороне коммутатор смог определить, к какому VNI данный пакет относится — то есть выполняет по сути роль VLAN тега. Что дальше? Логично было бы как и в GRE упаковать оригинальный фрейм с VxLAN заголовком в IP пакет. Но тут возникает проблема. В заголовке протокола IP есть поле protocol, как не трудно догадаться, отвечает данное поле за то, какой вышестоящий протокол упакован в данный IP пакет. GRE заголовок является протоколом номер 47, а вот VxLAN номера не имеет. То есть по сути упаковать VxLAN напрямую в IP можно, но это вызовет сложности при обработке пакета как на транзитных узлах, так и на узле назначения. Поэтому VxLAN пакет, как например и GTP, предварительно упаковывается в UDP, в котором поля protocol нет. И теперь нам ничего не мешает упаковать полученный UDP сегмент в IP пакет. Под VxLAN специально был выделен UDP порт 4789.
Возникает вопрос — почему UDP? Почему не TCP, он же надежнее, имеет адские таймауты для сессий и т д. Дело в том, что TCP проектировался под совсем другие нужны и его задача — гарантированная доставка данных приложений — отсюда и механизмы подтверждения получения пакета удаленной стороной и управление скоростью передачи. Проблема хорошо будет заметна, когда клиент тоже будет использовать TCP. В итоге мы получим TCP поверх TCP — уже звучит не очень. Теперь представьте, что пакеты теряются, и как вы понимаете, теряться они будут и в рамках underlay сессии VTEP-A<<>>VTEP-B и в рамках overlay сессии SERVER-A<<>>SERVER-B. А когда у нас теряются пакеты в TCP, то закономерно возникают ретрансмиты — так как нет подтверждения получения. В итоге возникнут ретрансмиты и в underlay сессии и в overlay сессии. То есть получается, что underlay TCP сессия начнет гонять помимо своих ретрансмит пакетов, еще и ретрансмиты overlay TCP сессии. В итоге в таком сценарии мы погрязнем в ретрансмитах, что неизбежно приведет к потере скорости и в итоге получим вместо плюсов — одни минусы. К тому же еще одним не менее важным фактором в пользу UDP является тот факт, что UDP не устанавливает сессию, когда TCP — это всегда p2p сессия и она не может быть p2mp — а вот зачем нам это, мы узнаем чуть позже.
Сам VxLAN заголовок имеет следующий вид:
По сути нам интересно тут только поле VNI.
Как я и написал выше, далее нам ничего не мешает упаковать UDP сегмент в IP отправить… Но отправить куда? Не на деревню дедушке ж. VxLAN тоннели строятся между лупбеками коммутаторов, поэтому сорс адрес будет собственный лупбек коммутатора. А вот как узнать лупбеки удаленных коммутаторов, выполняющих роль VTEP? То есть нам нужен механизм поиска соседей.
Механизм поиска соседей может быть автоматическим или ручным (если ручной можно вообще назвать поиском соседей). VxLAN имеет несколько режимов работы. Рассмотрим их по порядку.
Static (Unicast) VxLAN
Самый простой вариант — это статичное указание удаленных VTEP. Этот режим схож с VPLS Martini. Все сводится к тому, что в конфигурации VNI надо статически задать адреса всех удаленных VTEP, которые терминируют клиентов в указанном VNI. В таком сценарии VTEP будет указывать в IP заголовке как адреса назначения — адреса указанных вручную VTEP. Естественно, если VTEP-ов будет больше двух, то точек назначения пакета при флуде будет уже как минимум две. Указать в IP заголовке нескольких получателей не получится, поэтому самым простым решением будет репликация VxLAN пакета на исходящем VTEP и отправка их юникастом на удаленные VTEP-ы, указанные в конфигурации. Получив данный пакет, удаленный VTEP его декапсулирует, определяет какому VNI данный пакет относится и далее рассылает его во все порты в данном VNI (точнее действует так, как было описано ранее в разборе работы коммутатора). Помимо этого, так как мы все в курсе, что mac адреса изучаются коммутаторами на основании поля source mac, то после декапсуляции VxLAN пакета VTEP ассоциирует mac адрес, указанный как исходящий в оригинальном ethernet заголовке с тоннелем до VTEP, от которого данный пакет получен. Как и было написано ранее — VxLAN тоннель коммутатор воспринимает как простой транковый порт.
Минусы данного подхода очевидны — это увеличенная нагрузка на сеть, так как BUM трафик реплицируется на исходящем VTEP и юникастом рассылается всем указанным в конфигурации нейборам, плюс к этому при добавлении или удалении VTEP придется править конфиги на всех остальных VTEP-ах и руками удалить или добавить нейбора (нейборов). В век автоматизации как-то странно использовать статическое указание нейборов. Но все равно данный подход имеет право на жизнь, например openvswitch умеет работать только со статически заданным нейбором, во всяком случае на данный момент (поправьте если не прав).
Для работы данного режима необходимо только наличие связности между лупбеками всех VTEP. В практической части мы познакомимся с конфигурацией и работой VxLAN в данном режиме.
Multicast VxLAN
Данный режим работы, в отличии от предыдущего, умеет находить удаленные VTEP-ы автоматически, а репликация бродкаста происходит на underlay, а не на исходящем VTEP. И репликация и поиск удаленных VTEP-ов происходит с помошью мультикаста. Теперь нам не надо вручную указывать всех нейборов, а вместо этого указать какую-то мультикаст группу, которая будет ассоциирована с конкретным VNI (или несколькими VNI). После того, как группа будет привязана к VNI, коммутатор (точнее VTEP, так как им может быть и простой сервер) начинает слушать данную группу. Но что нам это дает? Логично, что точно так же поступят и остальные VTEP-ы (если конечно вы правильно укажите соответствие VNI-multicast группа) — они станут слушать указанную вами группу. И если послать какой пакет на адрес этой группы, то его получат все VTEP-ы. Этот функционал и позволяет нам реплицировать пакеты и искать удалённые VTEP-ы.
В итоге все работает просто и банально — VTEP формирует VxLAN пакет, указывая себя источником (свой лупбек в IP заголовке), а адрес назначения устанавливает равный адресу сконфигуренной для данного VNI мультикаст группы — то есть получается, что VTEP теперь еще становится и сорсом для данной группы. Далее работает обычный и всеми нами любимый мультикаст. Так как все остальные VTEP слушают данную группу, то все они получают VxLAN пакет. Ну а далее все тоже самое, что и раннее — декапсуляция оригинального фрейма, изучение мака (так как сорсом для данной группы VTEP указывает себя, то удаленным VTEP-ам не составляет труда ассоциировать mac с тоннелем до исходящего VTEP) и флудинг.
Теперь снова вернемся к инкапсуляции VxLAN в UDP и вопросу — почему же UDP? Как вы поняли у нас получилась p2mp соединение – один источник и несколько получателей. TCP не умеет устанавливать p2mp сессии, в отличии от UDP, который сессию вообще не устанавливает.
Как правило бест-практикс считается использование bidir-PIM, что более чем логично, так как VTEP одновременно является и получателем и источником мультикаст группы (или нескольких групп в зависимости от вашего конфига). Естественно тут так же работает правило расщепления горизонта — пакет, полученный через VxLAN тоннель не будет отправлен обратно в VxLAN тоннель.
В сравнении с первым вариантом в данном сценарии BUM трафик реплицируется на underlay и естественно будет занимать меньше полосы пропускания. К тому же теперь нейборов задавать руками нет необходимости. Для работы данного режима необходимо наличие связности до удаленных VTEP по IP и поддержка мультикаста. Если у вас что-то не взлетело (как вы понимаете ломаться тут особо, то и нечему) — то для начала проверьте, а верно ли вы сконфигурили связку VNI-мультикаст группа. Как все это конфигурируется мы разберем на практическом примере.
EVPN/VxLAN
Третий вариант, он же самый интересный и масштабируемый — это использование EVPN как control plane для VxLAN. Если кто-то не знает, что же такое EVPN, то советую почитать мою предыдущую статью, хотя она и относится к концепции MPLS/EVPN, основные принципы работы справедливы и для VxLAN/EVPN. Сегодня глубоко раскапывать EVPN/VxLAN я не буду – ограничимся основными моментами.
Как я написал выше, основа EVPN — это великий и могучий (или многострадальный) протокол BGP, который и позволяет производить изучение маков между VTEP-ами и поиск соседей. Так как этот зверь может таскать любые маршруты, и даже передавать link-state информацию (до чего дошел прогресс), то что ему стоит перенести информацию о mac адресах? Под EVPN выделено отдельное сабсемество адресов в семействе l2vpn (AFI 25). Это позволило превратить mac адрес в аналог роутингового адреса и передавать его в BGP анонсах — то есть так же, как это делается в L3VPN. При использовании EVPN/MPLS в BGP NLRI передавался сам mac адрес (естественно не забываем про RT/RD/next-hop и т д ) и MPLS метка. Сейчас нам метка ни к чему — у нас нет MPLS. А она нам и не нужна, потому что у нас есть VNI! Вопрос только в том, как вместо метки в BGP сообщении закодировать VNI.
EVPN NLRI под метку не случайно отведено 3 байта — то есть 24 бита, это идеально подходит для указания VNI. Поэтому вместо метки в BGP анонсе логично занял место метки идентификатор VNI. Единственная проблема, которую надо решить — как коммутатор, который получит данный EVPN маршрут должен узнать, что в поле MPLS Label закодирован именно VNI, а не MPLS метка? Ведь по умолчанию там метка и коммутатор будет полностью прав, восприняв значение этого поля как метку. Снимая дамп в Wireshark вы будете видеть не VNI, а MPLS метку (при кодировании метки последние 4 бита не используются, поэтому Wireshark считает что в поле закодирована метка 6, а не VNI 100):
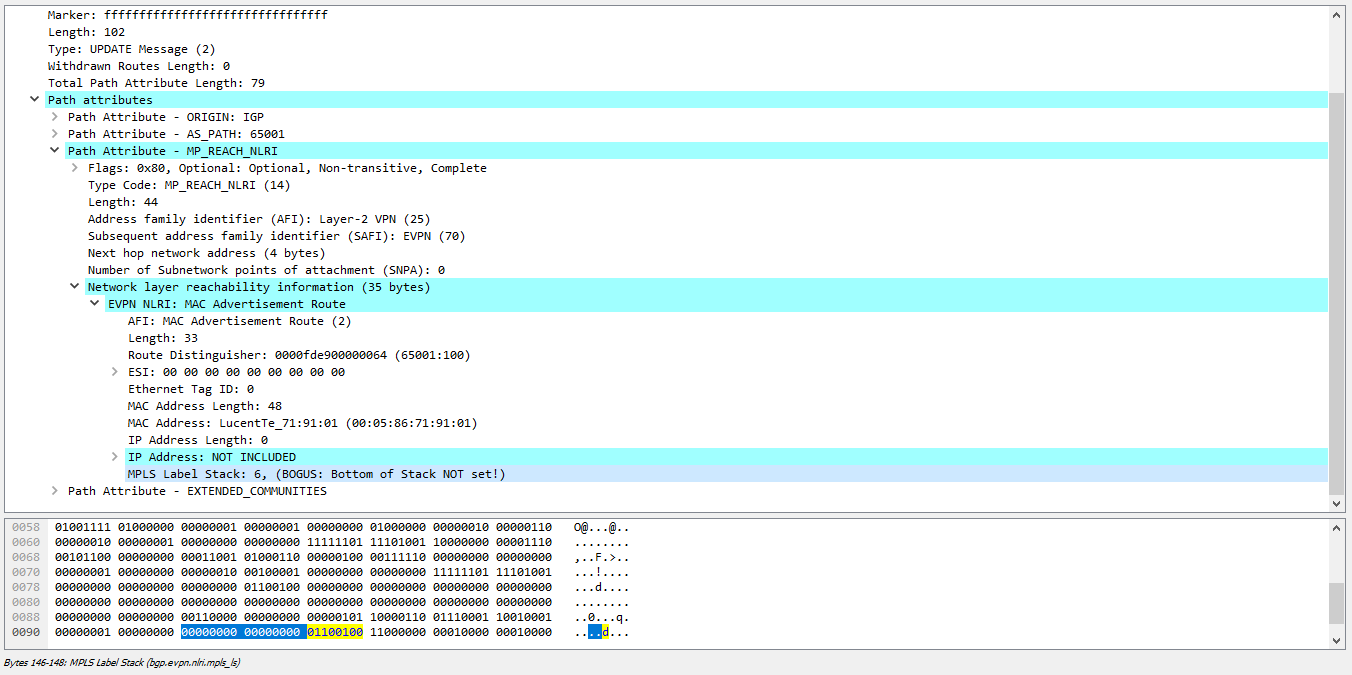
Чтобы побороть данную проблему используется специальное расширенное комьюнити, которое указывает, что данный маршрут необходимо использовать именно для vxlan инкапсуляции:
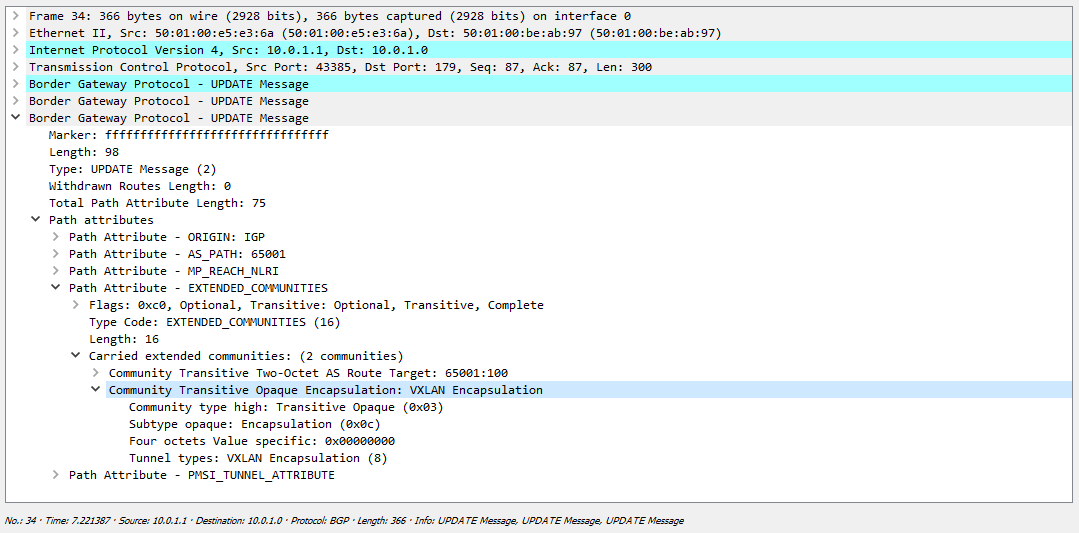
И если мы сейчас поле, отведенное под метку переведем в десятичную систему, то получим наш VNI:
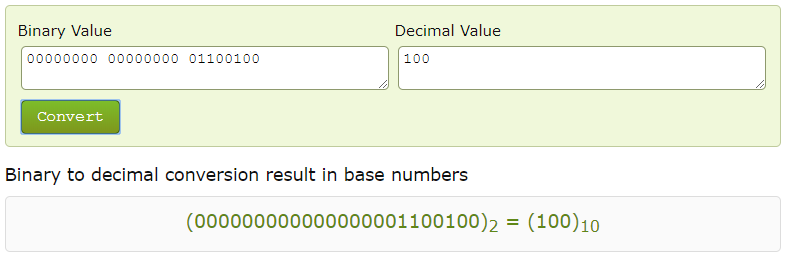
Остальные принципы работы примерно такие же — те же 5-ть типов маршрутов (если честно, то маршрутов на данный момент уже 8 типов, но часть из них еще в статусе драфта). По-умолчанию, если у вас в ядре нет мультикаста, то будет работать репликация на исходящем узле (исходящем VTEP), как это мы рассмотрели в первом варианте. Но при наличии мультикаста репликация будет производится не на исходящем узле, а где-то дальше (на RP как правило, либо в других точка, если есть более короткие пути до источника чем через RP).
Отдельно хотелось бы сказать про изучение маков. Какие плюсы у EVPN? Как правило везде пишут в первых строках фразу следующего содержания — EVPN переносит изучение мак адресов с data plane на control plane. Звучит очень гордо и прогрессивно, но давайте подумаем, а так ли это на самом деле? Во-первых, изучение маков на участке Клиент-VTEP происходит, как правило, на data-plane. Далее, что происходит, когда коммутатор получает фрейм? Правильно, он его флудит во все порты, кроме тех, за которыми клиента точно нет (по мнению коммутатора).
Концепция EVPN подразумевает следующее поведение — когда какой то из удаленных VTEP-ов изучил mac адрес через data plane, он формирует BGP сообщение, в котором указывает данный мак и рассылает его своим пирам. Все остальные VTEP-ы, приняв это BGP сообщение инсталлируют полученный mac в таблицы форвардинга. Что это нам дает? А то, что теперь у коммутатора есть причина отправить фрейм только в один порт, а не во все, так как он точно знает, где живет mac назначения. А вот то, что узнал он это через control plane — нам абсолютно не важно.
Но все же меняется ли что нибудь в модели поведения коммутатора и если да, то на сколько велик масштаб изменений? Да, коммутатор, получив какой-то фрейм и изучив mac адрес, формирует BGP сообщение с указанием данного мака и рассылает его своим пирам — то есть рассказывает всем, что за мной такой то mac. Но если коммутатор еще не знает где живет mac адрес назначения, то он логично все так же флудит полученный фрейм во все порты. То есть изучение маков методом flood-and-learn никуда не делось, более того даже при наличии EVPN изучение маков все так же работает методом флуда, но просто теперь изученные через data-plane маки передаются между коммутаторами через control plane. В итоге EVPN позволяет существенно сократить объем флуда при изучении маков, но никак не избавиться от него полностью.
Что еще хорошего дает нам EVPN? Технология позволяет нам упростить жизнь сетевого инженера, так как предоставляет функционал автоматического поиска соседей.
Еще одной очень важно функцией EVPN является мультихоминг, как Single-Active, так и All-Active (причем один сервер может смотреть в два и более коммутатора в отличии от MC-LAG). Мультихоминг может быть организован или пропириетарными средствами вендора (MLAG -Arista, vPC – Cisco Nexus), или стандартными средствами EVPN. Первый случай нам сейчас не интересен — давайте обсудим зашитый в EVPN механизм мультихоминга. В принципе все сводится к тому, как избавиться от L2 петли (при All-Active, в Single-Active это не нужно) — алиасинг и ускорение сходимости при отказе собственно уже красивый и функциональный обвес. Как вы уже знаете, для этого в сегменте выбирается DF — это узел, который имеет право отправлять BUM трафик в сторону клиента. Все остальные узлы просто дропают BUM трафик, предназначенный клиенту. Но проблема будет тогда, когда клиент отправит бродкатный фрейм в сторону non-DF узла и тот его перешлет в сторону DF. Логично, что далее DF вернет фрейм клиенту, что приведет к петле.
В EVPN/MPLS эта проблема решена простым добавлением ESI метки в стек — если в стеке есть такая метка, то DF не станет отправлять трафик обратно в сегмент, из которого трафик получен. Но в VxLAN нет меток. Че делать? Механизм защиты от петель тут несколько изменен.
Как и в EVPN/MPLS интерфейсы, которые смотрят в один и тот же сегмент должны иметь один и тот же идентификатор — ESI. После обмена маршрутами типа 4, узлы находят своих партнеров по ESI (в отличии от MC-LAG их может быть больше двух) и выбирают DF, который будет слать широковещательный трафик в сегмент. Так как у нас нет меток, но мы знаем адреса соседей по ESI, то при получении широковещательного фрейма, коммутатор сначала смотрит, с какого сорс адреса прилетел пакет (то есть из какого туннеля). Если пакет прилетел от VTEP-а, который у него указан, как сосед по ESI, то фрейм в сторону клиента не отправляется. Как правило этот механизм реализован на уровне железа и носит название local bias. О нюансах выбора DF и мультихоминге в целом можете прочитать в моих предыдущих статьях.
Также к несомненным плюсам EVPN можно отнести и уже упомянутые вскользь механизмы, обеспечивающие быструю сходимость в случае отказа (Mass Withdrawal), балансировку трафика в сторону сервера, если его mac виден только через одно плечо (Aliasing), расширенный L3 функционал и anycast GW, возможность переноса виртуальных машин без остановки сервиса.
VxLAN с использованием контроллера
Еще одним режимом работы является управление с контроллера. В таком сценарии настройка VTEP сводится к указанию адреса контроллера, а поиск соседей и прочий сопутствующий функционал реализуется контроллером. Рассматривать данный режим в практической части я не буду, просто потому, я думаю всем и так понятно, как это в принципе будет работать, а что бы все это продемонстрировать, необходимо запустить сам контроллер.
Подведем итог всего того, что было написано. Получается, что в VxLAN как underlay используется простая IP сеть (даже можно и без мультикаста), то есть роль end-to-end тоннеля выполняет IP связность между лупбеками VTEP-ов. Как туннелирующий протокол для создания overlay сети используется udp совместно с VxLAN. Поиск соседей может производиться или вручную (указание в конфигурации неборов), или автоматически — с помощью мультикаста (маппинг VNI к мультикаст группе) и EVPN, или с помощью выделенного контроллера.
После того, как мы разобрались с тем, как происходит инкапсуляция оригинального L2 пакета в VxLAN и передача его через IP фабрику, осталось подсчитать, какой же оверхед у нас получается. Да, забыл важную деталь, которую стоит учесть: в RFC указано, что при получении фрейма оригинальный vlan тег должен быть снят, и уже фрейм без тега упаковываться в VxLAN. И это работает по умолчанию, например, для Cisco Nexus или Juniper QFX. Сделано это для того, что бы можно было без накручивания всяких rewrite-ов и трансляций тега использовать различные номера вланов на разных VTEPах. То есть грубо говоря сделать влан локальным для коммутатора. Например на VTEP A VNI 100 соответствует влану 100, в то же время на VTEP B VNI 100 соответствует влану 200. VxLAN тоннели в такой конфигурации поднимутся, но если не снимать влан тег, то без трансляции вланов на одном из VTEP (ну например на VTEP B тег 200 транслируется в 100 на приеме, а на передачу наоборот — тег 100 в тег 200) у вас ничего не заработает. В практической части вы увидите, что в одном и том же VNI у меня на разных VTEP будут разные вланы.
Примечание: данное поведение можно изменить, если вам это надо (пример при использовании vlan-bundle метода конфигурирования VNI – то есть это создание одного виртуального свича и нескольких бридж доменов – в таком сценарии у вас будет один и тот же VxLAN тоннель для всех бридж-доменов, и что бы при получении фрейма VTEP мог понять, к какому именно бридж домену относится фрейм, нам нужно оригинальный тег сохранить
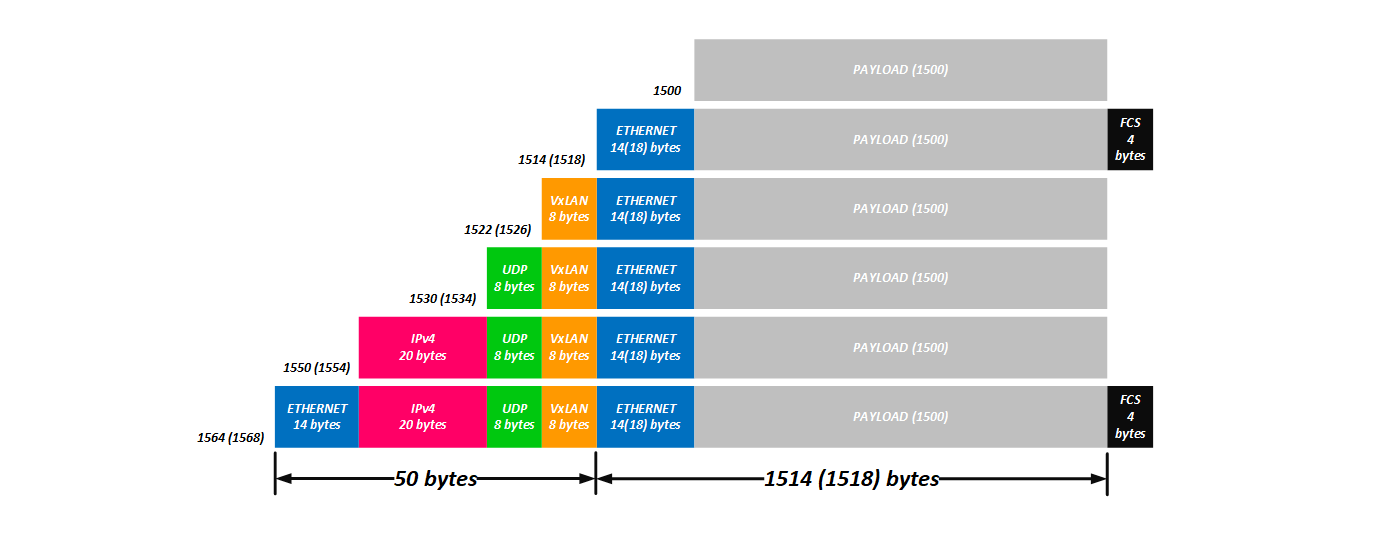
Итак, считаем, что у нас с заголовками:
8 байт (VxLAN заголовок) + 8 байт (UDP заголовок) + 20 байт (IPv4 заголовок) + 14 байт (внешний L2 заголовок) = 50 байт (54 c сохранением клиентского тега).
Да, как-то так, немалый оверхед. Но если в сети будут использованы Jumbo фреймы, то этот заголовок не так уж и велик.
С другой стороны, если взять NVGRE, то у данной технологии тоже немаленький оверхед:
4 байта (тег клиента, который остается после инкапсуляции) + 8 байт (GRE) + 20 байт (IPv4) + 14 байт (L2) = 46 байта
или VPLS:
4 байта (внутренняя MPLS метка) + 4 байта (внешняя MPLS метка) + 14 байт (L2 заголовок) = 22 байта (26 байт при использовании нормализации влан тега или сохранения тега клиента).
Всякие срабатывания FRR или, например, BGP-LU метки мы не будем учитывать, как говорится в известном фильме: «Забирайте, государство не обеднеет»
В любом случае, если сервера будут обмениваться 64-х байтными пакетами, то оверхед у любой из указанных выше технологий будет большим, но при использовании пакетов разметом 4000-9000 байт — все не так страшно, как кажется.
В итоге, перечислим, какие же плюсы имеет VxLAN в сравнении с обычной L2 сетью (вне зависимости от того, какой тип мы используем):
- 1. Нет необходимости в протоколе семейства STP;
- 2. Быстрая сходимость в случае отказа узла или линка;
- 3. Увеличенное количество L2 доменов (4K vs 16M);
- 4. Балансировка трафика по эквивалентным путям (ECMP);
- 5. L2 можно растянуть на несколько площадок;
- 6. При добавлении нового влана нет необходимости лезть на все коммутаторы и тащить по ним нужный влан (не забываем про адскую подставу в синтаксисе циски — switchport trunk без ключевого слова add — и не говорите, что не разу на это не попадались) — в VxLAN конфигурация делается только на VTEP.
Собственно говоря, на этом с теорией мы на сегодня завяжем и перейдем к практике.
Многие у меня спрашивают, почему я всегда использую в своих статьях только синтаксис JunOS? И правда, почему, подумал я. Сегодня у нас в лабе будут нет, не Джуны, и даже не Циски. Сегодня мы покопаемся в Аристах, ну а почему бы и нет? Ну а для любителей Цискоджунов в статье будут представлены конфиги и с этого оборудования для сравнения.
Практическая часть
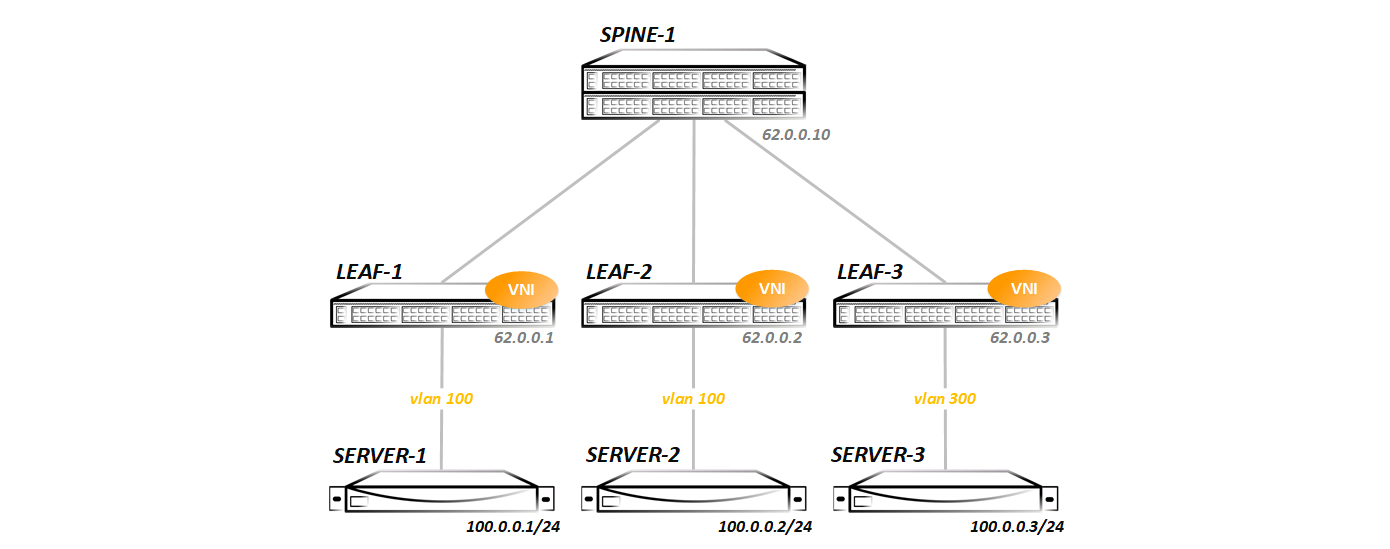
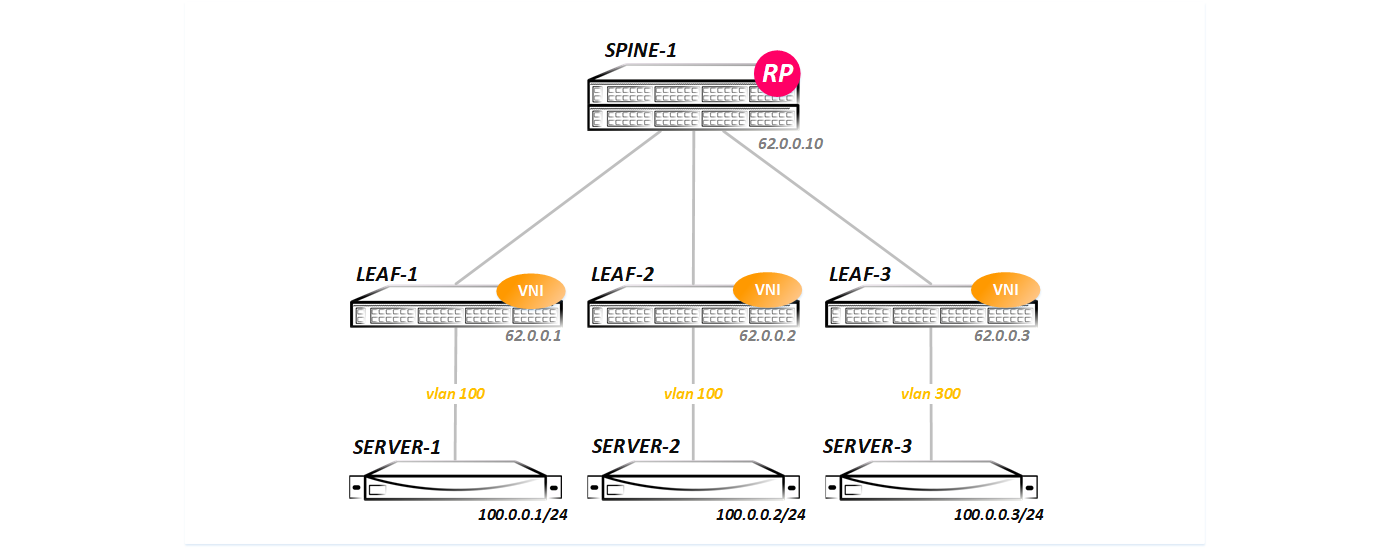
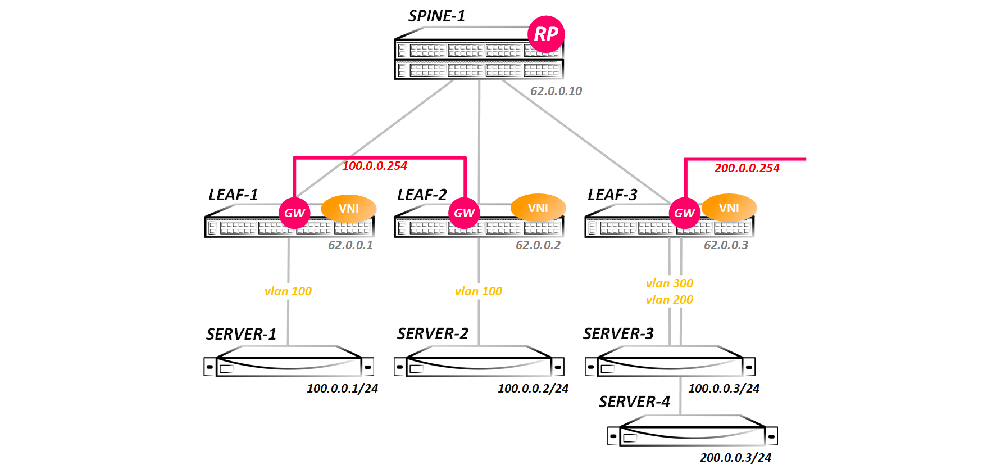
В всех трех тестах будем рассматривать такую топологию:
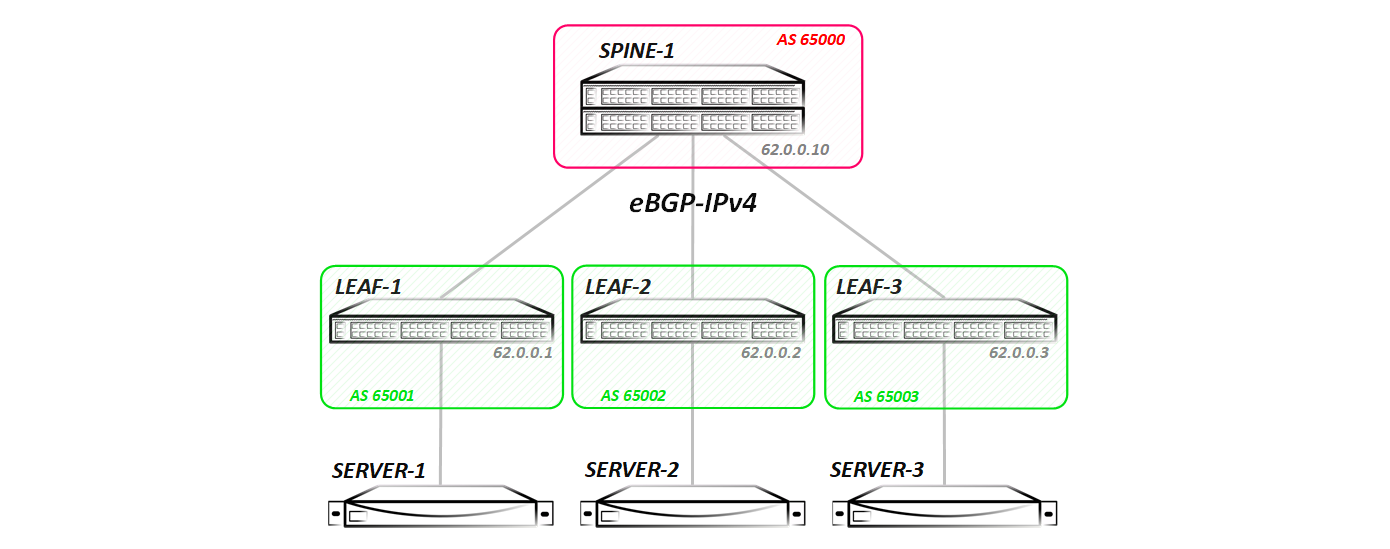
То есть у нас простейшая топология Клоза — один Spine и три Leaf-а. В такой топологии проще всего снять дамп и увидеть весь обмен трафиком (так как при добавлении второго спайна у нас появляется ECMP и дамп пришлось бы снимать сразу на двух линках), да и объяснить, как это все работает проще всего на такой топологии.
Со стороны Spine мы видим по lldp все три Leaf-а:
Spine-1#show lldp neighbors
Last table change time : 0:09:43 ago
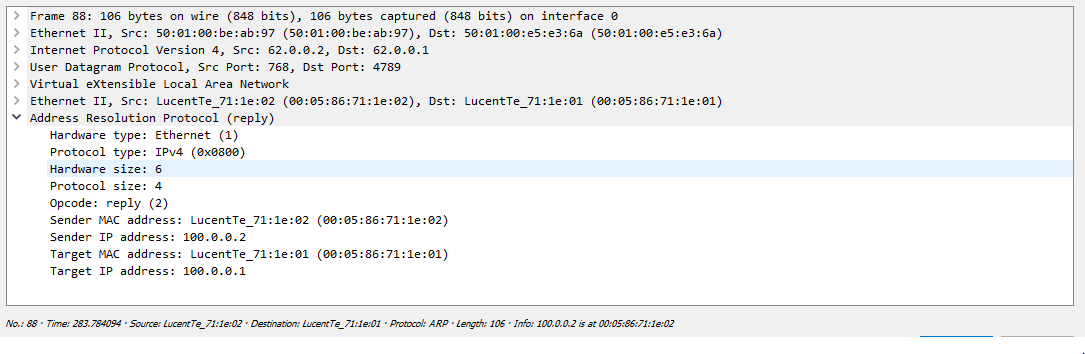
Number of table inserts : 3
Number of table deletes : 0
Number of table drops : 0
Number of table age-outs : 0
Port Neighbor Device ID Neighbor Port ID TTL
Et1 Leaf-1 Ethernet1 120
Et2 Leaf-2 Ethernet1 120
Et3 Leaf-3 Ethernet1 120IGP в привычном виде — ISIS/OSPF/EIGRP я не запускал, для этой цели использован BGP — между Spine и Leaf нодами натянуты eBGP ipv4 сессии:
Spine-1#show ip bgp summary
BGP summary information for VRF default
Router identifier 62.0.0.10, local AS number 65000
Neighbor Status Codes: m - Under maintenance
Neighbor V AS MsgRcvd MsgSent InQ OutQ Up/Down State PfxRcd PfxAcc
10.0.1.1 4 65001 14 16 0 0 00:09:23 Estab 3 3
10.0.2.1 4 65002 14 16 0 0 00:09:21 Estab 3 3
10.0.3.1 4 65003 14 16 0 0 00:09:19 Estab 3 3В BGP включена редистрибуция всех конектед сетей (вообще то для работы VxLAN нужны только лупбеки, но я анонсировал все, чтобы потом протестировать маршрутизацию). В дальнейшем мы будем менять конфигурации — добавлять новые семейства адресов, запускать мультикаст и т д. Каждый тест будем начинать с чистой топологии, представленной выше (все конфиги, которые будут сделаны в предыдущем тесте будут удалены, дабы было понятно, что и зачем мы запускаем).
Ну и начнем с банального:
Static (Unicast) VxLAN
Идем по порядку. Создаваем влан 100 и разрешаем его на интерфейсе в сторону сервера:
vlan 100
name VNI-1
!
interface Ethernet5
description Server-1
switchport trunk allowed vlan 100
switchport mode trunkТеперь нам надо ассоциировать vlan 100 с каким то vni (что бы долго не думать я выбрал vni 100 — вы можете взять любой, хоть 1 хоть 16 миллионов — это не важно). Для этого создаем виртуальный интерфейс vxlan1:
interface Vxlan1
vxlan source-interface Loopback0
vxlan udp-port 4789
vxlan vlan 100 vni 100
vxlan vlan 100 flood vtep 62.0.0.2 62.0.0.3vxlan 1 — это тоннельный интерфейс, который предназначен для термирации VxLAN тоннелей. На Cisco аналогичный интерфейс называется nve (network virtualized interface), на Junos – vtep (расшифровывать, думая не надо), но как вы понимаете, название несет лишь смысловую нагрузку — принцип работы от этого не меняется.
В конфигурации vxlan интерфейса мы указываем какой vlan в какой vni маппится:
vxlan vlan 100 vni 100В нашем случае влан 100 в VNI 100.
Так как у нас статический VxLAN, то нам надо указать все удаленные VTEP-ы, что видно в последней строке конфига vxlan интерфейса:
vxlan vlan 100 flood vtep 62.0.0.2 62.0.0.3На схеме видно, что в сторону Server-3 используется не влан 100, а влан 300. Поэтому на Leaf-3 конфиг несколько отличается:
vlan 300
name VNI-1
!
interface Ethernet5
description Server-1
switchport trunk allowed vlan 300
switchport mode trunk
!
interface Vxlan1
vxlan source-interface Loopback0
vxlan udp-port 4789
vxlan vlan 300 vni 100
vxlan vlan 300 flood vtep 62.0.0.1 62.0.0.2 Собственно, вот все. Дальше проверяем, что все завелось.
В данный момент все спокойно — никакого обмена трафиком между хостами не было, о чем говорит отсутствие маков в таблице форвардинга:
Leaf-1#show mac address-table vlan 100 unicast Mac Address Table ------------------------------------------------------------------ Vlan Mac Address Type Ports Moves Last Move ---- ----------- ---- ----- ----- --------- Total Mac Addresses for this criterion: 0Хотя все vtep-ы прописаны нами статически:
Leaf-1#show vxlan flood vtep
VXLAN Flood VTEP Table
--------------------------------------------------------------------------------
VLANS Ip Address
----------------------------- ------------------------------------------------
100 62.0.0.2 62.0.0.3но коммутатор еще их не видит, так как обмена еще не было:
Leaf-1#show vxlan vtep
Remote VTEPS for Vxlan1:
Total number of remote VTEPS: 0Тут поведение у разных вендоров отличается — Nexus или QFX вам сразу покажут, что они видят удаленные VTEP, если они будут доступны по IP. Arista покажет нам наличие удаленных VTEP только после того, как будет произведён какой-либо обмен.
Итого, имеем вот такую суммарную информацию по сконфигуренным нами VNI (у нас он один):
Leaf-1#show interfaces vxlan 1
Vxlan1 is up, line protocol is up (connected)
Hardware is Vxlan
Source interface is Loopback0 and is active with 62.0.0.1
Replication/Flood Mode is headend with Flood List Source: CLI
Remote MAC learning via Datapath
Static VLAN to VNI mapping is
[100, 100]
Note: All Dynamic VLANs used by VCS are internal VLANs.
Use 'show vxlan vni' for details.
Static VRF to VNI mapping is not configured
Headend replication flood vtep list is:
100 62.0.0.3 62.0.0.2Что мы собственно можем сказать по данному выводу? Мы используем loopback0 с адресом 62.0.0.1 как сорс для vxlan тоннелей, флуд фреймов происходит согласно указанному нами в CLI списку удаленных VTEP-ов, vlan 100 статически мапится в VNI 100, ну и в конце сам список сконфигуренных нами VTEP-ов.
На Leaf-2 все практически тоже самое (только список пиров другой, что логично), а на Leaf-3 изменений, как мы уже увидели больше, поэтому приведу вывод с него. Как видите, на Leaf-3 влан 300 маппится в тот же vni 100:
Leaf-3#show vxlan vni 100
VNI to VLAN Mapping for Vxlan1
VNI VLAN Source Interface 802.1Q Tag
--------- ---------- ------------ --------------- ----------
100 300 static Ethernet5 300
Note: * indicates a Dynamic VLANLeaf-3#show interfaces vxlan 1
Vxlan1 is up, line protocol is up (connected)
Hardware is Vxlan
Source interface is Loopback0 and is active with 62.0.0.3
Replication/Flood Mode is headend with Flood List Source: CLI
Remote MAC learning via Datapath
Static VLAN to VNI mapping is
[300, 100]
Note: All Dynamic VLANs used by VCS are internal VLANs.
Use 'show vxlan vni' for details.
Static VRF to VNI mapping is not configured
Headend replication flood vtep list is:
300 62.0.0.1 62.0.0.3Теперь запустим пинг между серверами и посмотрим, взлетит ли схема или нет:
bormoglotx@ToR> ping logical-system Server-1 source 100.0.0.1 100.0.0.2 rapid
PING 100.0.0.2 (100.0.0.2): 56 data bytes
!!!!!
--- 100.0.0.2 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 59.807/119.973/338.390/109.381 msbormoglotx@ToR> ping logical-system Server-1 source 100.0.0.1 100.0.0.3 rapid
PING 100.0.0.3 (100.0.0.3): 56 data bytes
!!!!!
--- 100.0.0.3 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 64.941/89.089/157.432/35.149 msПинги проходят — связность через тоннели есть. Посмотрим таблицы mac адресов на коммутаторах:
Leaf-1#show vxlan address-table dynamic vlan 100
Vxlan Mac Address Table
----------------------------------------------------------------------
VLAN Mac Address Type Prt VTEP Moves Last Move
---- ----------- ---- --- ---- ----- ---------
100 0005.8671.1e02 DYNAMIC Vx1 62.0.0.2 1 0:00:36 ago
100 0005.8671.1e03 DYNAMIC Vx1 62.0.0.3 1 0:00:32 ago
Total Remote Mac Addresses for this criterion: 2Два mac адреса выучены динамически и видны через тоннельный интерфейс, а если быть точнее, то через VxLAN тоннель до Leaf-2 и Leaf-3.
Сама же таблица мак адресов имеет такой вид:
Leaf-1#show mac address-table vlan 100 unicast
Mac Address Table
------------------------------------------------------------------
Vlan Mac Address Type Ports Moves Last Move
---- ----------- ---- ----- ----- ---------
100 0005.8671.1e01 DYNAMIC Et5 1 0:00:54 ago
100 0005.8671.1e02 DYNAMIC Vx1 1 0:00:54 ago
100 0005.8671.1e03 DYNAMIC Vx1 1 0:00:50 ago
Total Mac Addresses for this criterion: 3В обоих случая вы видите таймеры. Через определенное время (по умолчанию 300 секунд бездействия) мак будет удален — тут все стандартно.
После того, как произошел обмен трафиком, Leaf-1 нашел двух соседей:
Leaf-1#show vxlan vtep
Remote VTEPS for Vxlan1:
62.0.0.2
62.0.0.3
Total number of remote VTEPS: 2А вот Leaf-3 (как впрочем и Leaf-2) видит только одного нейбора:
Leaf-3#show vxlan vtep
Remote VTEPS for Vxlan1:
62.0.0.1
Total number of remote VTEPS: 1Это логично и нормально, так как обмена трафиком между сервером 2 и 3 не было.
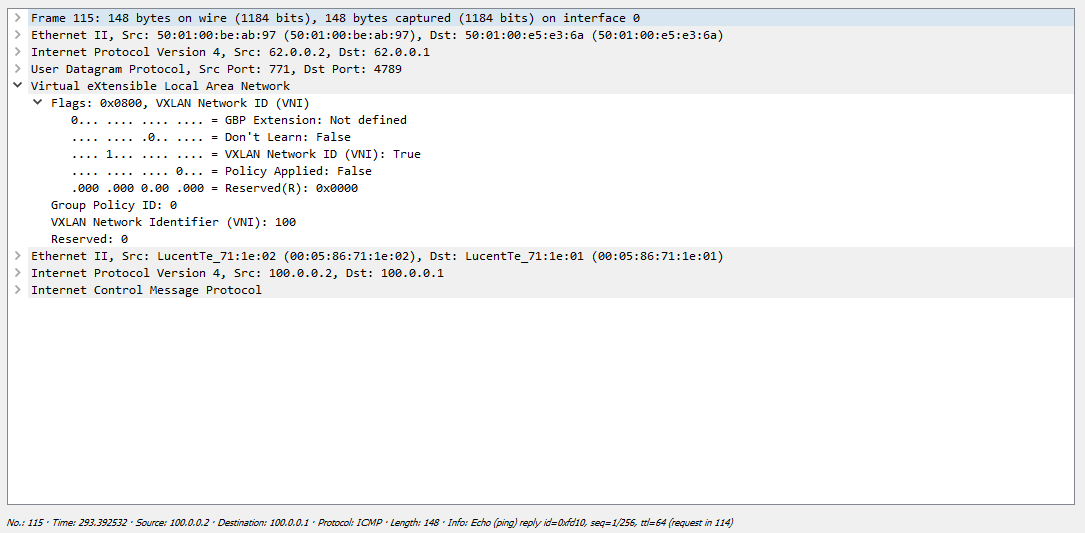
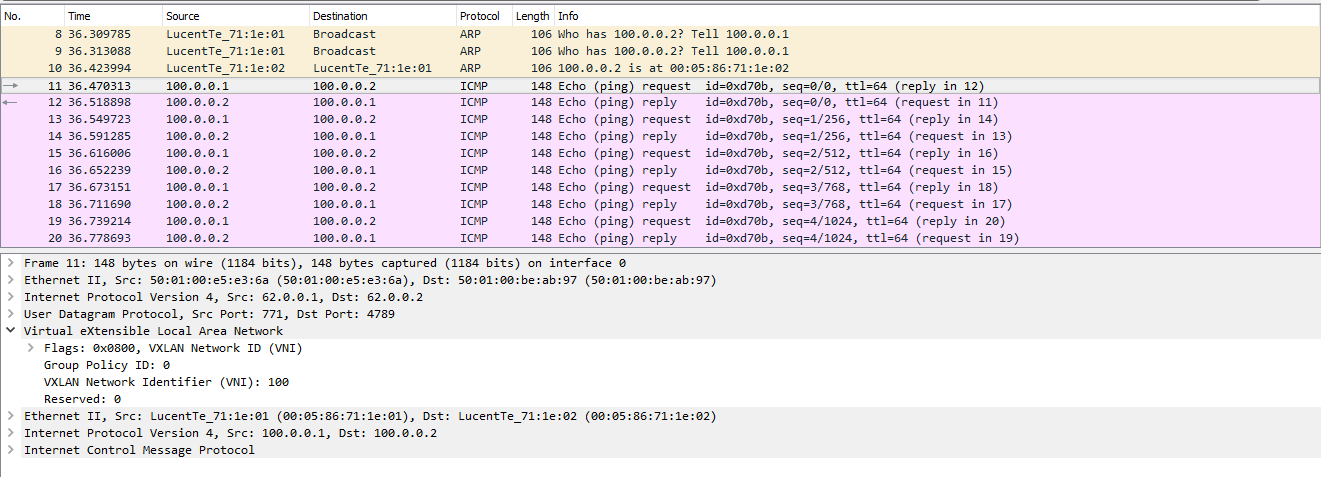
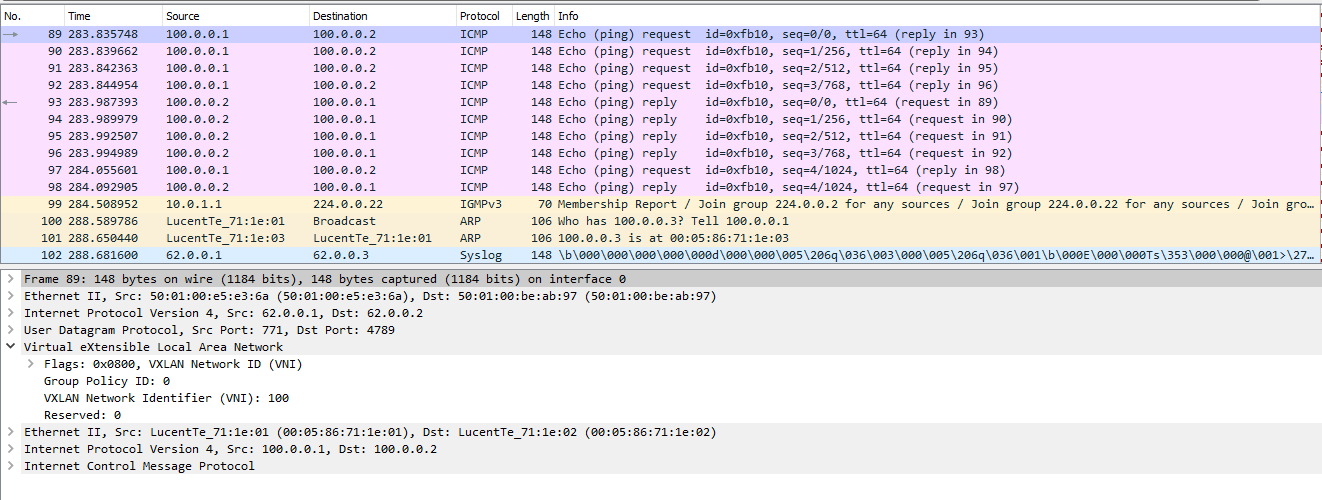
Теперь посмотрим, как это будет выглядеть при снятии дампа на линке между Leaf-1 и Spine-1. Весь обмен выглядит следующим образом:

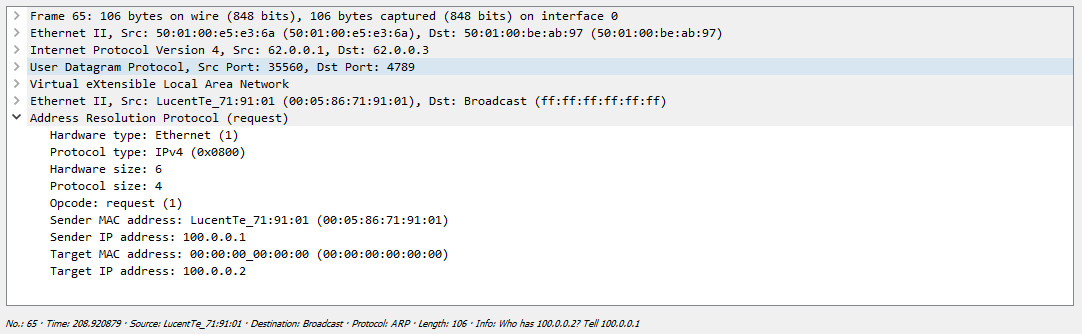
Сначала Сервер формирует ARP запрос, который коммутатор должен разослать всем удаленным VTEP-ам. Как мы выяснили ранее репликация происходит на исходящем узле с дальнейшей рассылкой пакета юникастом:
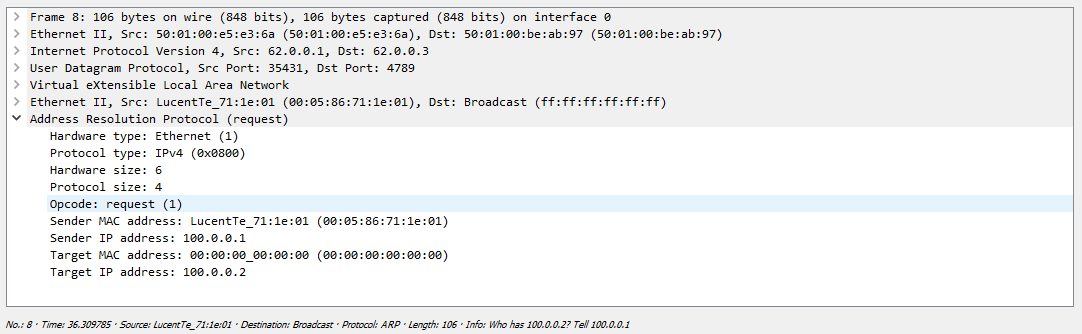
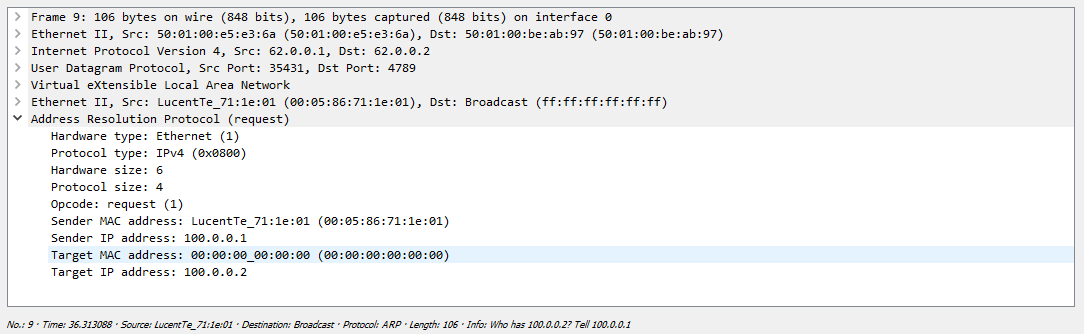
Один их серверов просто дропает полученный пакет, так как этот запрос адресован не ему, а вот второй сервер благополучно отвечает:
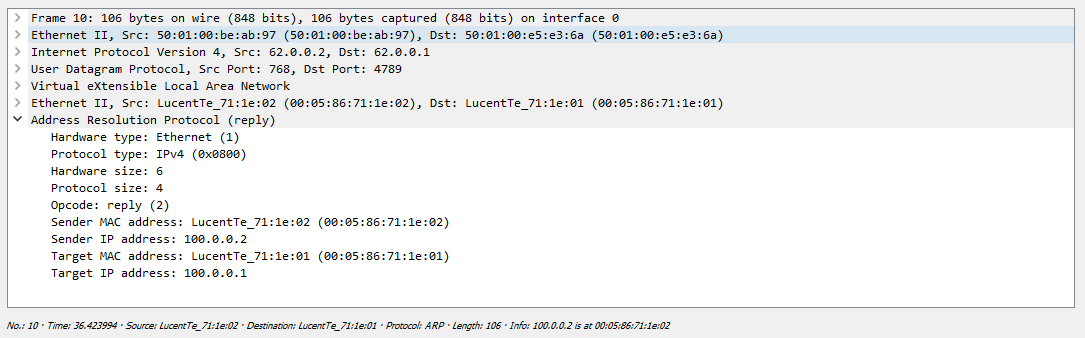
После этого оба сервера знают mac адреса друг друга и могу начать обмен трафиком, в нашем случае ICMP:
Теперь сделаем шлюз для выхода во внешнюю сеть с VRRP:
Leaf-1#show running-config interfaces vlan 100
interface Vlan100
ip address 100.0.0.252/24
vrrp 100 priority 128
vrrp 100 authentication text vlan100
vrrp 100 ip 100.0.0.254Leaf-2#show running-config interfaces vlan 100
interface Vlan100
ip address 100.0.0.253/24
vrrp 100 priority 64
vrrp 100 authentication text vlan100
vrrp 100 ip 100.0.0.254Leaf-1#show vrrp group 100 interface vlan 100
Vlan100 - Group 100
VRF is default
VRRP Version 2
State is Master
Virtual IPv4 address is 100.0.0.254
Virtual MAC address is 0000.5e00.0164
Mac Address Advertisement interval is 30s
VRRP Advertisement interval is 1s
Preemption is enabled
Preemption delay is 0s
Preemption reload delay is 0s
Priority is 128
Authentication text, string "vlan100"
Master Router is 100.0.0.252 (local), priority is 128
Master Advertisement interval is 1s
Skew time is 0.500s
Master Down interval is 3.500s Теперь запустим пинг сервера 3 до шлюза:
bormoglotx@ToR> ping logical-system Server-3 source 100.0.0.3 100.0.0.254 rapid
PING 100.0.0.254 (100.0.0.254): 56 data bytes
!!!!!
--- 100.0.0.254 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 56.915/75.978/134.126/29.286 msШлюз доступен. Так как у нас vlan интерфейс в grt, то проанонсировав этот адрес по BGP мы можем достучаться до других сетей, например до лупбека своего же Leaf-3:
bormoglotx@ToR> ping logical-system Server-3 source 100.0.0.3 62.0.0.3 rapid
PING 62.0.0.3 (62.0.0.3): 56 data bytes
!!!!!
--- 62.0.0.3 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 93.210/111.745/138.930/16.970 msПуть трафика в таком сценарии имеет следующий вид: пакет с сервера по дефолтному маршруту попадает на Leaf-3. Так как мак адрес шлюза, который указан как адрес назначения, Leaf-3 знает через VxLAN тоннель до Leaf-1, то пакет через этот тоннель улетает на Leaf-1. Далее, Leaf-1 декапсулирует пакет, и видит, что адрес назначения 62.0.0.3, маршрут до которого ему известен в grt через bgp. Далее пакет маршрутизируется обратно на Leaf-3. Ответ от лупбека Leaf-3 возвращается таким же путем.
Как видите, технология VxLAN, а особенно в рассмотренном нами варианте -Static (Unicast) VxLAN — проста как валенок и безотказна, как автомат Калашникова. Ну а чему тут ломаться собственно говоря?
Для примера приведу конфиги с Cisco и Juniper:
На Cisco Nexus все более-менее похоже на конфигурацию Arista — во всяком случае подход тот же. Создаем nve интерфейс (аналог vxlan) и нужный нам влан:
vlan 100
name VNI-100
vn-segment 100interface nve1
no shutdown
source-interface loopback0
member vni 100
ingress-replication protocol static
peer-ip 62.0.0.2
peer-ip 62.0.0.3Далее разрешаем данный влан в сторону клиента и все готово. Естественно, так как это Nexus не забываем включать нужные нам фичи:
interface Ethernet1/2
description Server-1 | LS-3
switchport mode trunk
switchport trunk allowed vlan 100feature bgp
feature vn-segment-vlan-based
feature lldp
feature nv overlayНа Juniper QFX все немного иначе (ну это же джунипер). В иерархии switch-options указываем сорс для VxLAN тоннеля и адреса удаленных VTEP:
switch-options {
vtep-source-interface lo0.0;
remote-vtep-list [ 62.0.0.2 62.0.0.3 ];
}vlans {
VLAN400 {
vlan-id 400;
vxlan {
vni 16000100;
ingress-node-replication;
}
}
}Далее разрешаем данный влан в сторону клиента и все готово.
Думаю, с этим разобрались. Теперь перейдем ко второму варианту — будем использовать мультикаст для автоматического поиска соседей и репликации BUM трафика.
Multicast VxLAN
Как нетрудно догадаться, для начала нам надо запустить PIM. Spine будем использовать как RP, так как у него идеальное местоположение в топологии для выполнения данной функции. Не буду выпендриваться и настрою статическую RP, да и spine у меня всего один:
ip pim rp-address 62.0.0.10
!
interface Ethernet1
ip pim sparse-modeТак как мы удалили весь конфиг, который мы сделали в первом тесте, то нам надо снова создать нужный влан (100 влан на Leaf-1/2 и 300 — на Leaf-3), и разрешить их в сторону сервера (конфиг показывать не буду, вы и так его уже видели). Теперь создаем vxlan интерфейс:
interface Vxlan1
vxlan multicast-group 230.0.0.100
vxlan source-interface Loopback0
vxlan udp-port 4789
vxlan vlan 100 vni 100Как и в прошлый раз vlan 100 соответствует vni 100 (на Leaf-3 vlan 300 соответствует vni 100). Теперь нам надо ассоциировать vni 100 с mgroup 230.0.0.100. Получилась такая цепочка — vlan 100 >> vni 100 >>> mgroup 230.0.0.100.
Вот и вся конфигурация. Проверим, что наша конфигурация взлетит. Посмотрим, поднялось ли на RP соседство со всеми leaf-ми:
Spine-1#show ip pim neighbor
PIM Neighbor Table
Neighbor Address Interface Uptime Expires Mode
10.0.1.1 Ethernet1 00:03:53 00:01:20 sparse
10.0.2.1 Ethernet2 00:03:55 00:01:19 sparse
10.0.3.1 Ethernet3 00:03:52 00:01:21 sparseОтлично, нейборы видны. Смотрим суммарную информацию по vxlan:
Leaf-1#show interfaces vxlan 1
Vxlan1 is up, line protocol is up (connected)
Hardware is Vxlan
Source interface is Loopback0 and is active with 62.0.0.1
Replication/Flood Mode is multicast
Remote MAC learning via Datapath
Static VLAN to VNI mapping is
[100, 100]
Note: All Dynamic VLANs used by VCS are internal VLANs.
Use 'show vxlan vni' for details.
Static VRF to VNI mapping is not configured
Multicast group address is 230.0.0.100Тут уже метод репликации и флуда указан — мультикаст, а вместо листа с перечислением всех удаленных VTEP — только мультикаст группа. Для Leaf-3 все аналогично с поправкой на номер влана:
Leaf-3#show vxlan vtep
Remote VTEPS for Vxlan1:
Total number of remote VTEPS: 0
Leaf-3#show interfaces vxlan 1
Vxlan1 is up, line protocol is up (connected)
Hardware is Vxlan
Source interface is Loopback0 and is active with 62.0.0.3
Replication/Flood Mode is multicast
Remote MAC learning via Datapath
Static VLAN to VNI mapping is
[300, 100]
Note: All Dynamic VLANs used by VCS are internal VLANs.
Use 'show vxlan vni' for details.
Static VRF to VNI mapping is not configured
Multicast group address is 230.0.0.100Так как мы уже знаем, как должен работать VxLAN через мультикаст, то по правилам после того, как мы сконфигурили vxlan интерфейс и добавили ассоциацию vlan<<>>VNI, Leaf-ы должны вступить в группу 230.0.0.100:
Leaf-1#show ip mroute
PIM Bidirectional Mode Multicast Routing Table
RPF route: U - From unicast routing table
M - From multicast routing table
PIM Sparse Mode Multicast Routing Table
Flags: E - Entry forwarding on the RPT, J - Joining to the SPT
R - RPT bit is set, S - SPT bit is set, L - Source is attached
W - Wildcard entry, X - External component interest
I - SG Include Join alert rcvd, P - (*,G) Programmed in hardware
H - Joining SPT due to policy, D - Joining SPT due to protocol
Z - Entry marked for deletion, C - Learned from a DR via a register
A - Learned via Anycast RP Router, M - Learned via MSDP
N - May notify MSDP, K - Keepalive timer not running
T - Switching Incoming Interface, B - Learned via Border Router
RPF route: U - From unicast routing table
M - From multicast routing table
230.0.0.100
0.0.0.0, 0:00:05, RP 62.0.0.10, flags: W
Incoming interface: Ethernet1
RPF route: [U] 62.0.0.10/32 [200/0] via 10.0.1.0
Outgoing interface list:
Loopback0Видим запись (*,G) — то есть Leaf-1 хочет получать трафик мультикаст группы 230.0.0.100 и не важно, кто будет сорсом для данной группы. Так как не было обмена трафиков, то в таблице форвадинга на коммутаторе маков тоже нет:
Leaf-1#show vxlan address-table
Vxlan Mac Address Table
----------------------------------------------------------------------
VLAN Mac Address Type Prt VTEP Moves Last Move
---- ----------- ---- --- ---- ----- ---------
Total Remote Mac Addresses for this criterion: 0Как и нет известных удаленных VTEPов:
Leaf-1#show vxlan vtep
Remote VTEPS for Vxlan1:
Total number of remote VTEPS: 0Запустим пинг между серверами и проверим сам факт наличия связности, ну и соответственно наличие маков в таблицах VTEP-ов:
bormoglotx@ToR> ping logical-system Server-1 100.0.0.2 rapid
PING 100.0.0.2 (100.0.0.2): 56 data bytes
!!!!!
--- 100.0.0.2 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 57.521/69.366/82.147/10.469 msbormoglotx@ToR> ping logical-system Server-1 100.0.0.3 rapid
PING 100.0.0.3 (100.0.0.3): 56 data bytes
!!!!!
--- 100.0.0.3 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 59.762/81.369/164.374/41.505 msСвязность есть, а судя по выводу ниже, Leaf-1 нашел два удаленных VTEP-а:
Leaf-1#show vxlan vtep
Remote VTEPS for Vxlan1:
62.0.0.2
62.0.0.3
Total number of remote VTEPS: 2Логично, что адреса серверов 2 и 3 будут видны через vxlan тоннель:
Leaf-1#show vxlan address-table vlan 100
Vxlan Mac Address Table
----------------------------------------------------------------------
VLAN Mac Address Type Prt VTEP Moves Last Move
---- ----------- ---- --- ---- ----- ---------
100 0005.8671.1e02 DYNAMIC Vx1 62.0.0.2 1 0:00:47 ago
100 0005.8671.1e03 DYNAMIC Vx1 62.0.0.3 1 0:00:41 ago
Total Remote Mac Addresses for this criterion: 2Но все вышеописанное мы уже как бы видели и в прошлом тесте — где же отличия? Отличия дальше. Так как Leaf-1 отправил трафик на адрес группы 230.0.0.100, то мы должны увидеть, что данный коммутатор стал сорсом для данной группы:
Spine-1#show ip pim upstream joins
Neighbor address: 10.0.1.1
Via interface: Ethernet1 (10.0.1.0)
Group: 230.0.0.100
Joins:
62.0.0.1/32 SPT
Prunes:
No prunes includedТеперь переместимся на Leaf-3, и посмотрим, какие группы прослушивает данный коммутатор:
Leaf-3#show ip mroute
PIM Bidirectional Mode Multicast Routing Table
RPF route: U - From unicast routing table
M - From multicast routing table
PIM Sparse Mode Multicast Routing Table
Flags: E - Entry forwarding on the RPT, J - Joining to the SPT
R - RPT bit is set, S - SPT bit is set, L - Source is attached
W - Wildcard entry, X - External component interest
I - SG Include Join alert rcvd, P - (*,G) Programmed in hardware
H - Joining SPT due to policy, D - Joining SPT due to protocol
Z - Entry marked for deletion, C - Learned from a DR via a register
A - Learned via Anycast RP Router, M - Learned via MSDP
N - May notify MSDP, K - Keepalive timer not running
T - Switching Incoming Interface, B - Learned via Border Router
RPF route: U - From unicast routing table
M - From multicast routing table
230.0.0.100
0.0.0.0, 0:03:48, RP 62.0.0.10, flags: W
Incoming interface: Ethernet1
RPF route: [U] 62.0.0.10/32 [200/0] via 10.0.3.0
Outgoing interface list:
Loopback0
62.0.0.1, 0:01:50, flags: S
Incoming interface: Ethernet1
RPF route: [U] 62.0.0.1/32 [200/0] via 10.0.3.0
Outgoing interface list:
Loopback0Тут мы видим запись типа (*,G), которая была ранее (она нам говорит о том, что коммутатор слушает группу 230.0.0.100 и ему не важно, кто источник). А вот вторая запись уже имеет вид (S,G), которая нам говорит, что коммутатор слушает группу 230.0.0.100 с адресом сорса 62.0.0.1.
Теперь посмотрим дамп, чтобы увидеть весь обмен, так сказать, в живую:
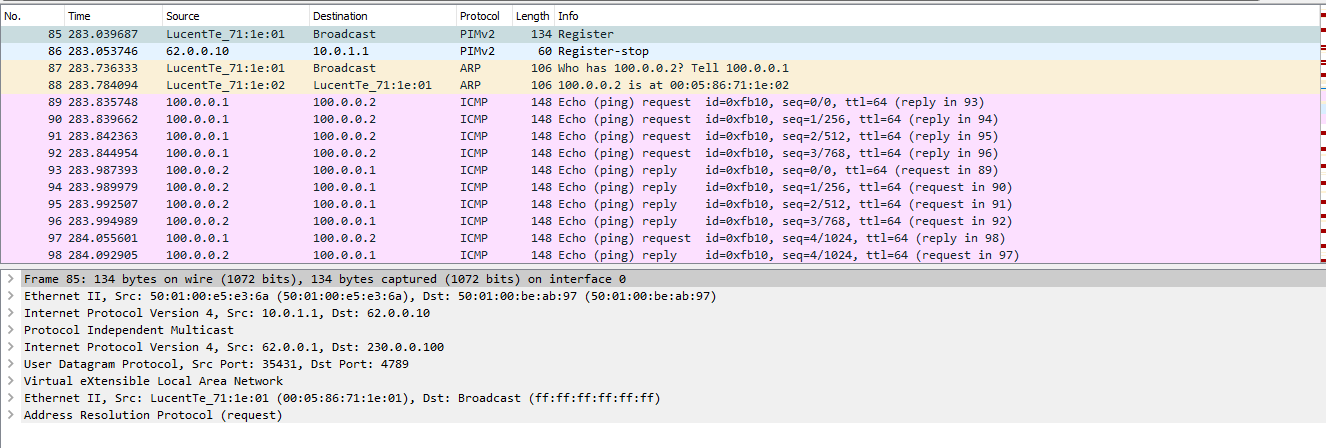
Весь обмен выглядит несколько иначе, чем в первом случае. Сначала происходит отправка сообщения на адрес мультикаст группы:
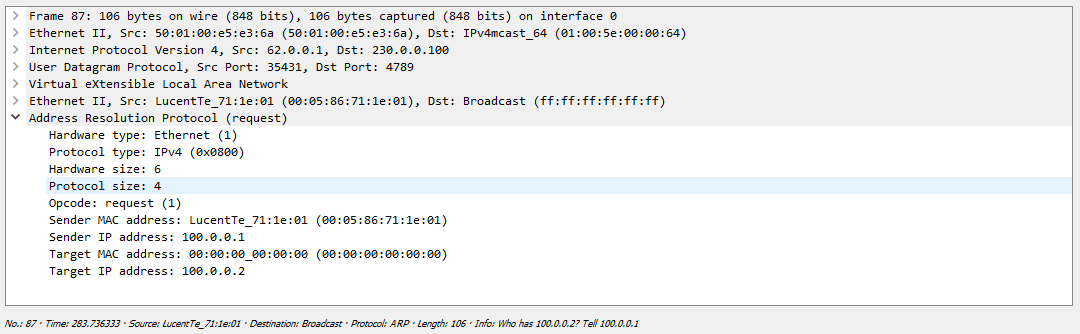
В дампе хорошо видны сообщения PIM Register и Register-stop – то есть работа мультикаста в чистом виде.
Далее мы видим ответ от удаленного сервера, но уже юникастом:
Ну и после чего следует обмен трафиком:
Теперь добавим в схему еще один сервер — Server-4, подключим его к Leaf-3 и поместим в VNI 200:
> Конфигурация на Leaf-3 несколько изменилась:
Leaf-3(config-if-Vx1)#show active
interface Vxlan1
vxlan multicast-group 230.0.0.100
vxlan source-interface Loopback0
vxlan udp-port 4789
vxlan vlan 200 vni 200
vxlan vlan 300 vni 100Хочу заметить, что оба VNI будут использовать одну и ту же мультикаст группу.
Теперь при попытке посмотреть информацию по VxLAN интерфейсу, мы видим, что теперь у нас два VNI:
Leaf-3#show interfaces vxlan 1
Vxlan1 is up, line protocol is up (connected)
Hardware is Vxlan
Source interface is Loopback0 and is active with 62.0.0.3
Replication/Flood Mode is multicast
Remote MAC learning via Datapath
Static VLAN to VNI mapping is
[200, 200] [300, 100]
Note: All Dynamic VLANs used by VCS are internal VLANs.
Use 'show vxlan vni' for details.
Static VRF to VNI mapping is not configured
Multicast group address is 230.0.0.100Влан 200 мапится во VNI 200, влан 300 в VNI 100. Смотрят они в один и тот же порт:
Leaf-3#show vxlan vni
VNI to VLAN Mapping for Vxlan1
VNI VLAN Source Interface 802.1Q Tag
--------- ---------- ------------ --------------- ----------
100 300 static Ethernet5 300
200 200 static Ethernet5 200
Note: * indicates a Dynamic VLANДалее создаем L3 интерфейсы. На Leaf-1/2 мы сделаем интерфейс vlan 100 с vrrp (как в прошлом тесте, конфиг повторно приводить не буду), а на Leaf-3 создадим гейт для VNI 200:
Leaf-3#show running-config interfaces vlan 200
interface Vlan200
ip address 200.0.0.254/24
Leaf-3#show vlan id 200
VLAN Name Status Ports
----- -------------------------------- --------- -------------------------------
200 VNI-200 active Cpu, Et5, Vx1 В итоге наша схема приобрела такой вид:
Теперь проверим, работает ли роутинг между VNI:
bormoglotx@ToR> ping logical-system Server-4 source 200.0.0.3 100.0.0.3
PING 100.0.0.3 (100.0.0.3): 56 data bytes
64 bytes from 100.0.0.3: icmp_seq=0 ttl=61 time=155.736 ms
64 bytes from 100.0.0.3: icmp_seq=1 ttl=61 time=117.702 ms
64 bytes from 100.0.0.3: icmp_seq=2 ttl=61 time=120.800 ms
64 bytes from 100.0.0.3: icmp_seq=3 ttl=61 time=127.033 ms
^C
--- 100.0.0.3 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/stddev = 117.702/130.318/155.736/15.055 msПуть трафик в данный момент такой — от Сервера-3 трафик улетает по дефолтному маршруту на mac адрес шлюза по умолчанию, которым является на Leaf-3. Коммутатор, получив пакет, декапсулирует его, и видит, что он предназначен ему самому (влан интерфейсу), далее происходит IP лукап. Так как хост 100.0.0.3 живет в сети 100.0.0.0/24, то трафик отправляется на Leaf-1, так как сеть назначения терминируется именно там (VRRP Master живет на Leaf-1). По IP сети через Spine пакет долетает до Leaf-1. Коммутатор, приняв IP пакет (не VxLAN а чистый IP), смотрит на адрес назначения и понимает, что он видит его через VxLAN тоннель до Leaf-3. Происходит инкапсуляция пакета в VxLAN и отправка на Leaf-3. Leaf-3, получает пакет, декапсулирует его, видит, что адрес назначения 100.0.0.3, который подключен к нему через интерфейс eth5, навешивает влан тег и отправляет в сторону сервера. Вот такой вот не оптимальный роутинг у нас получился, два сервера, живущие за одним и тем же интерфейсом, общаются через всю IP фабрику.
Как и в прошлой секции для примера конфигурации аналогичного сервиса с Cisco и Juniper: На Nexus все опять похоже на Arista. Так же создаем нужный нам влан и ассоциируем его с VNI:
vlan 100
name VNI-16000100
vn-segment 16000100И в nve интерфейсе указываем, какую мультикаст группу надо привязать к vni
interface nve1
no shutdown
source-interface loopback0
overlay-encapsulation vxlan
member vni 16000100
mcast-group 225.0.0.100Естественно включаем фичу PIM и непосредственно сам PIM на нужных интерфейсах. Далее прописывается влан в сторону клиента и все должно взлететь.
interface Ethernet1/2
description Server-1 | LS-3
switchport mode trunk
switchport trunk allowed vlan 100На Juniper QFX для начала надо включить pim на нужных интерфейсах (включая и Lo0), а так же включить тоннельные сервисы на каком то из FPC (необходимо для работы PIM):
pim {
rp {
static {
address 62.0.0.10;
}
}
interface xe-0/0/1.0 {
mode sparse;
}
interface lo0.0 {
mode sparse;
}
interface xe-0/0/2.0 {
mode sparse;chassis {
fpc 0 {
pic 0 {
tunnel-services {
bandwidth 40g;
}
}
}
}Далее конфигурация выглядит так:
{master:0}[edit]
bormoglotx@LEAF-101# show switch-options
vtep-source-interface lo0.0;{master:0}[edit]
bormoglotx@LEAF-101# show vlans
BRIDGE-4093 {
vlan-id 4093;
vxlan {
vni 4093;
multicast-group 230.0.40.93;
}
}Далее разрешаем данный влан в сторону клиента.
Думаю и с этим разобрались, поэтому движемся далее.
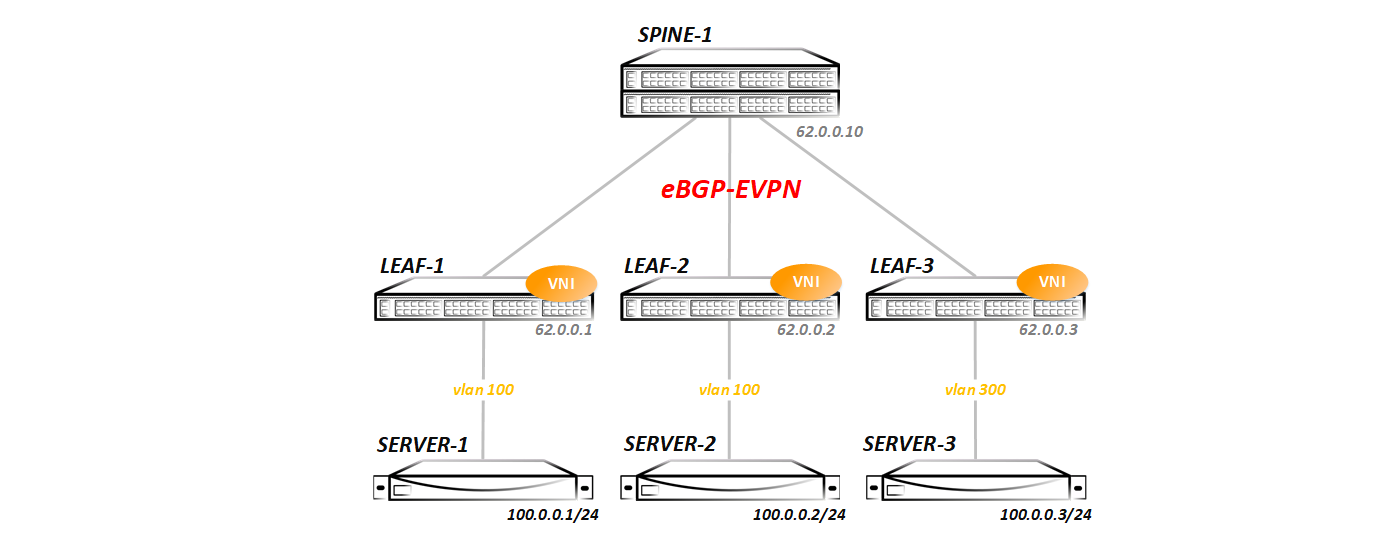
EVPN/VxLAN
Забыли предыдущую конфигурацию и делаем все заново:
Создаем влан 100 и разрешаем его на интерфейсе в сторону сервера:
Leaf-1#show running-config section vlan 100
vlan 100
name VNI-1
!
interface Ethernet5
description Server-1
switchport trunk allowed vlan 100
switchport mode trunkТеперь снова создаем vxlan интерфейс, но теперь нам надо указать только исходящий интерфейс для vxlna-тоннеля (как правило это один из лупбеков) и ассоциировать vlan 100 с vni 100:
interface Vxlan1
vxlan source-interface Loopback0
vxlan udp-port 4789
vxlan vlan 100 vni 100А далее переходим в bgp. Добавляем возможность пересылки расширенных комьюнити, включаем семейство адресов evpn и добавляем нейбора, которым является Spine-1:
router bgp 65001
neighbor 10.0.1.0 remote-as 65000
neighbor 10.0.1.0 description Spine-1
neighbor 10.0.1.0 soft-reconfiguration inbound all
neighbor 10.0.1.0 send-community extended
neighbor 10.0.1.0 maximum-routes 100
redistribute connected
!
vlan 100
rd 65001:100
route-target import 65002:100
route-target import 65003:100
route-target export 65001:100
redistribute learned
!
address-family evpn
neighbor 10.0.1.0 activate
!
address-family ipv4
neighbor 10.0.1.0 activateПоднять evpn сессию можно и на лупбеках (ibgp/ebgp multihop), но так как я использую ebgp, то мне без разницы, с чего поднимать сессию — если у меня упадет линк до спайна — то все и так встанет. Если у меня будет два спайна, то трафик полностью перейдет на второй спайн. К тому же у меня всего одна сессия с двумя семействами адресов — это уменьшает количество сессий (что несомненно проще траблшутить и эксплуатировать).
Из обычной конфигурации bgp выбивается иерархия vlan. Этот раздел конфигурации отвечает за создание evpn инстанса (EVI). Тут все просто — мы указываем rd (что бы клиенты могли использовать пересекающиеся номера вланов), rt — причем я сделал для наглядности для каждого VTEP свое комьюнити. Поэтому на импорт у нас два комьюнити — одно для принятия маршрутов от Leaf-2, второе — от Leaf-3. Команда redistribute learned отвечает за то, что как только коммутатор узнает мак через data plane, он его анонсирует через bgp. Точно также надо разрешить редистрибуцию и L3 интерфейсов. Но это уже специфика работы именно arista, например Juniper не требует таких команд.
На этом наш конфиг закончен. На остальных нодах конфиг такой же, за исключением того, что на Leaf-3 в vni 100 мапится vlan 300.
Проверим что мы в итоге сконфигурили:
Leaf-1#show interfaces vxlan 1
Vxlan1 is up, line protocol is up (connected)
Hardware is Vxlan
Source interface is Loopback0 and is active with 62.0.0.1
Replication/Flood Mode is headend with Flood List Source: EVPN
Remote MAC learning via EVPN
Static VLAN to VNI mapping is
[100, 100]
Note: All Dynamic VLANs used by VCS are internal VLANs.
Use 'show vxlan vni' for details.
Static VRF to VNI mapping is not configured
Headend replication flood vtep list is:
100 62.0.0.3 62.0.0.2Тут все логично, сорс — это loopback0 с адресом 62.0.0.1, для репликации и флуда используется список узлов, составленный с помошью EVPN. Vlan 100 маппится статически к VNI 100. И в самом конце мы видим тот самый список удаленных VTEP-ов, составленный с помошью EVPN. Эти же адреса мы можем увидеть в списке удалённых VTEP:
Leaf-1#show vxlan vtep
Remote VTEPS for Vxlan1:
62.0.0.2
62.0.0.3
Total number of remote VTEPS: 2Откуда коммутатор знает, что Leaf-2/3 являются его соседями по VxLAN домену? Для этого используется EVPN маршруты типа 3:
Leaf-1#show bgp evpn route-type ?
auto-discovery Filter by Ethernet Auto-Discovery (A-D) route (Type 1)
ethernet-segment Filter by Ethernet Segment Route (Type 4)
imet Filter by Inclusive Multicast Ethernet Tag Route (Type 3) <<<<
mac-ip Filter by MAC/IP advertisement route (Type 2) Один маршрут локальный — это мы сами сгенерированил, два других — это Inclusive Multicast Ethernet Tag маршруты от удаленных VTEP-ов:
Leaf-1#show bgp evpn route-type imet
BGP routing table information for VRF default
Router identifier 62.0.0.1, local AS number 65001
Route status codes: s - suppressed, * - valid, > - active, # - not installed, E - ECMP head, e - ECMP
S - Stale, c - Contributing to ECMP, b - backup
% - Pending BGP convergence
Origin codes: i - IGP, e - EGP, ? - incomplete
AS Path Attributes: Or-ID - Originator ID, C-LST - Cluster List, LL Nexthop - Link Local Nexthop
Network Next Hop Metric LocPref Weight Path
* > RD: 65001:100 imet 62.0.0.1
- - - 0 i
* > RD: 65002:100 imet 62.0.0.2
62.0.0.2 - 100 0 65000 65002 i
* > RD: 65003:100 imet 62.0.0.3
62.0.0.3 - 100 0 65000 65003 iПосмотрим детальную информацию по одному из маршрутов:
Leaf-1#show bgp evpn route-type imet vni 100 next-hop 62.0.0.2 detail
BGP routing table information for VRF default
Router identifier 62.0.0.1, local AS number 65001
BGP routing table entry for imet 62.0.0.2, Route Distinguisher: 65002:100
Paths: 1 available
65000 65002
62.0.0.2 from 10.0.1.0 (62.0.0.10)
Origin IGP, metric -, localpref 100, weight 0, valid, external, best
Extended Community: Route-Target-AS:65002:100 TunnelEncap:tunnelTypeVxlan
VNI: 100Мы видим AS-PATH (использование ebgp как overlay позволяет видеть, в какой автономке оригинировался и через какие прошел анонс мак адреса), протокол next-hop (не забываем, что у нас ebgp и Spine не должен менять эти next-hop-ы, иначе будет опция B и ниче не взлетит), что у нас используется инкапсуляция VxLAN (вот то самое комьюнити: TunnelEncap:tunnelTypeVxlan) и маршрут принадлежит VNI 100.
Пока что нам известно только куда флудить кадры (какие тоннели у нас построены автоматически и к какому VNI они относятся). Пока что никакого обмена трафиком не было и таблица мак адресов пуста:
Leaf-1#show mac address-table unicast vlan 100
Mac Address Table
------------------------------------------------------------------
Vlan Mac Address Type Ports Moves Last Move
---- ----------- ---- ----- ----- ---------
Total Mac Addresses for this criterion: 0Запустим пинг что бы проверить связность:
bormoglotx@ToR> ping logical-system Server-1 100.0.0.2 rapid
PING 100.0.0.2 (100.0.0.2): 56 data bytes
!!!!!
--- 100.0.0.2 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 72.731/94.632/115.048/13.476 msbormoglotx@ToR> ping logical-system Server-1 100.0.0.3 rapid
PING 100.0.0.3 (100.0.0.3): 56 data bytes
!!!!!
--- 100.0.0.3 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 67.071/99.286/177.772/40.933 msОтлично, трафик ходит. Теперь смотрим, что у нас с таблицами коммутации:
Leaf-1#show mac address-table
Mac Address Table
------------------------------------------------------------------
Vlan Mac Address Type Ports Moves Last Move
---- ----------- ---- ----- ----- ---------
100 0005.8671.9101 DYNAMIC Et5 1 0:00:36 ago
100 0005.8671.9102 DYNAMIC Vx1 1 0:00:35 ago
100 0005.8671.9103 DYNAMIC Vx1 1 0:00:19 ago
Total Mac Addresses for this criterion: 3Появились три мака, два из которых видны через VxLAN тоннель. Посмотрим, через какой именно тоннель видны данные маки:
Leaf-1#show vxlan address-table
Vxlan Mac Address Table
----------------------------------------------------------------------
VLAN Mac Address Type Prt VTEP Moves Last Move
---- ----------- ---- --- ---- ----- ---------
100 0005.8671.9102 EVPN Vx1 62.0.0.2 1 0:01:03 ago
100 0005.8671.9103 EVPN Vx1 62.0.0.3 1 0:00:48 ago
Total Remote Mac Addresses for this criterion: 2Все логично и просто. Но так как у нас EVPN, то у нас должны быть анонсы мак адресов. Посмотрим, что у нас известно через bgp:
Leaf-1#show bgp evpn route-type mac-ip
BGP routing table information for VRF default
Router identifier 62.0.0.1, local AS number 65001
Route status codes: s - suppressed, * - valid, > - active, # - not installed, E - ECMP head, e - ECMP
S - Stale, c - Contributing to ECMP, b - backup
% - Pending BGP convergence
Origin codes: i - IGP, e - EGP, ? - incomplete
AS Path Attributes: Or-ID - Originator ID, C-LST - Cluster List, LL Nexthop - Link Local Nexthop
Network Next Hop Metric LocPref Weight Path
* > RD: 65001:100 mac-ip 0005.8671.9101
- - - 0 i
* > RD: 65001:100 mac-ip 0005.8671.9101 100.0.0.1
- - - 0 i
* > RD: 65002:100 mac-ip 0005.8671.9102
62.0.0.2 - 100 0 65000 65002 i
* > RD: 65003:100 mac-ip 0005.8671.9103
62.0.0.3 - 100 0 65000 65003 iДва маршрута локальны — это не трудно понять по из AS Path, два получены от удаленных узлов.
Теперь снова посмотрим дамп обмена трафиком:

Но перед тем как все заработает, VTEP-ы должны обменяться IM маршрутами, которых в представленном дампе не видно, так как данные сообщения передаются сразу после установления BGP сессии (или после включения какого-то VNI в конфигурации). Для понимаю ниже представлю как выглядит одно из таких сообщений:
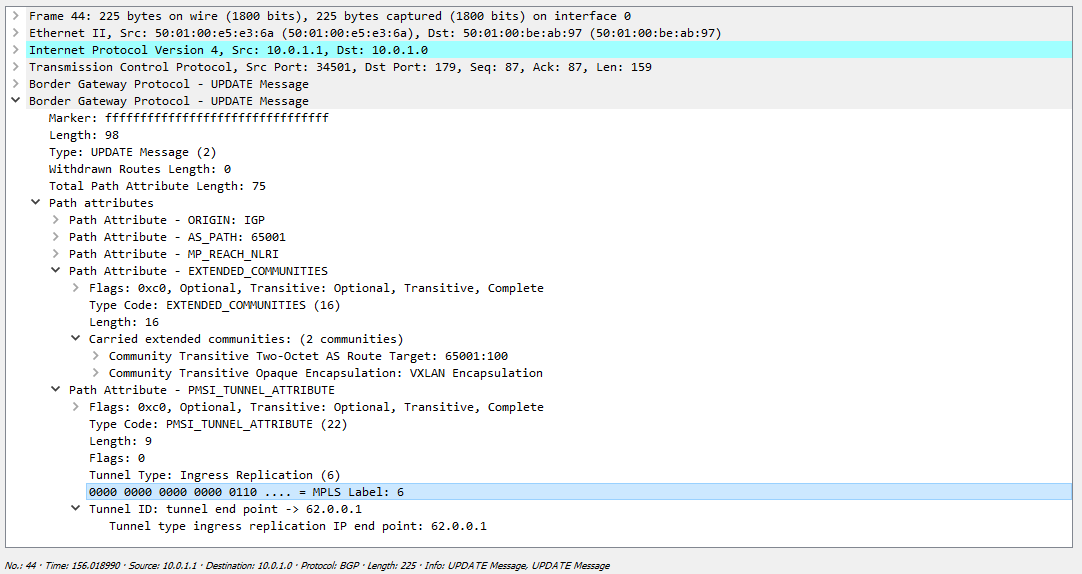
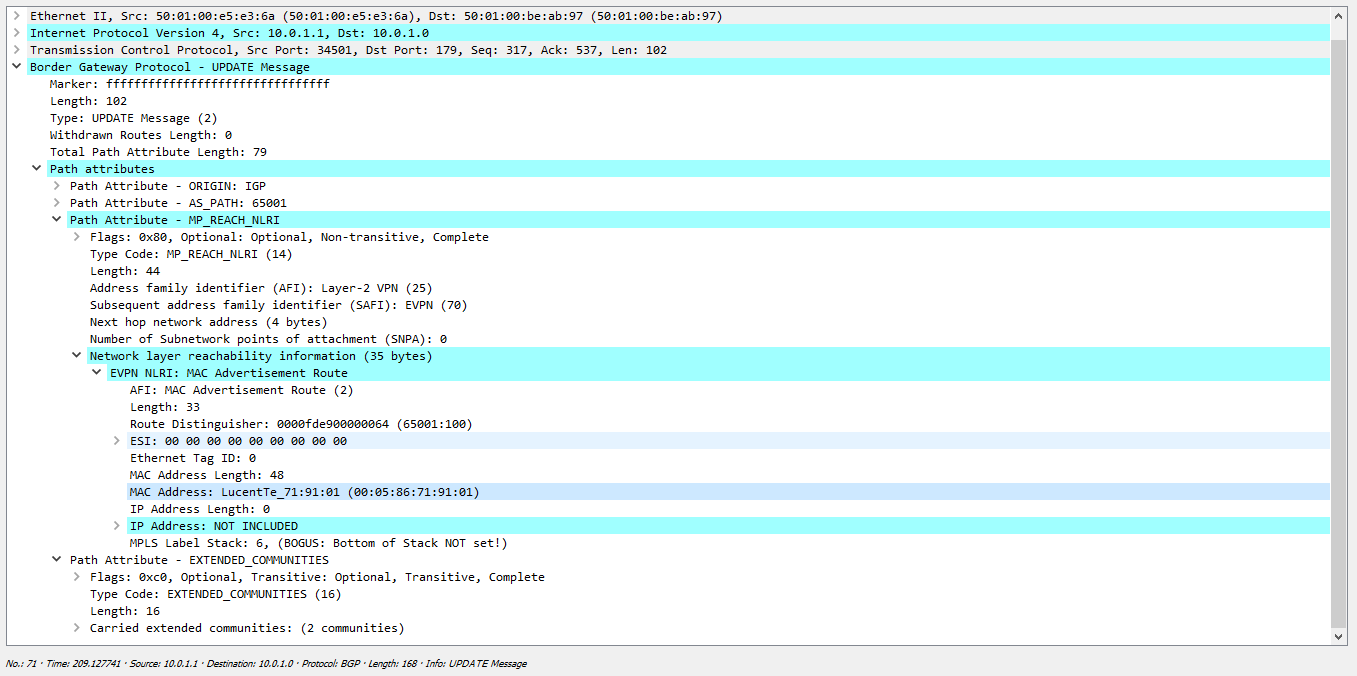
В сообщении мы видим, что у наc VNI 100 (помним, почему в дампе мы видим метку 6), а так же, что репликация происходит на узле 62.0.0.1 и для туннелирования необходимо использовать VxLAN.
Теперь вернемся непосредственно к обмену трафиком между серверами. Тут все более-менее похоже на первый случай, так как тут, так же как и в статическом VxLAN, репликация происходит на исходящем узле (напомню, что при наличии мультикаста, для репликации можно использовать его):
Далее мы видим ответ на ARP запрос:
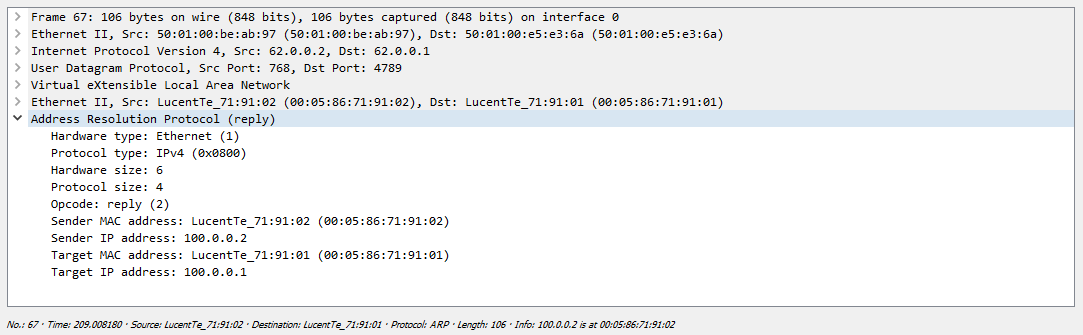
Но помимо этого в дампе видны BGP Upgrade сообщения. Как я писал ранее, если коммутатор изучил какой-то mac адрес через data plane, то он формирует BGP сообщение с указанием данного mac адреса:
Так как данные маршруты есть на всех трех коммутаторах — то все три коммутатора имеют маки указанных хостов в таблицах. То есть в прошлых двух вариантах изучение маков происходило исключительно на data-plane и если вы помните, то при обмене трафиком между узлами Server-1 c Server-2 и Server-3, на коммутаторах Leaf-2 и Leaf-3 у нас был только один удаленный мак — мак сервера, который живет за Leaf-1. Так как между серверами 2 и 3 обмена не было, то и маки друг друга они не знали. В дальнейшем, если сервер 2 захочет отправить пакет серверу 3, то трафик пойдет бродкастом, так как Leaf-2 не знает где живет сервер-3. В EVPN Leaf-2 и Leaf-3 ужу бутут иметь эти маки, так как получат их по BGP.
И пример настройки аналогичного сервиса на Cisco и Juniper:
На Cisco Nexus создаем влан и ассоциируем его с каким либо VNI:
vlan 100
name VNI-100
vn-segment 100Далее создем nve интерфейс, указывая, что использовать для сигнализации BGP (host-reachability protocol bgp):
interface nve1
no shutdown
source-interface loopback0
host-reachability protocol bgp
member vni 100
ingress-replication protocol bgpСтрока ingress-replication protocol bgp говорит о том, как производить репликацию. В данном случае репликация происходит на исходящем узле на основании данных о VTEP-ах, полученных через BGP. Далее создаем evpn инстанс (EVI):
evpn
vni 100 l2
rd 65001:100
route-target import 65001:100
route-target import 65002:100
route-target import 65003:100
route-target export 65001:100Ну и теперь разрешаем нужный влан в сторону клиента и проверям работу.
На Juniper QFX конфигурация выглядит примерно так (настройки bgp не показаны):
Когфигурация вланов:
{master:0}
bormoglotx@LEAF-101> show configuration vlans
BRIDGE-4093 {
vlan-id 4093;
vxlan {
vni 15000001;
ingress-node-replication;
}
}
BRIDGE-4094 {
vlan-id 4094;
vxlan {
vni 16000001;
ingress-node-replication;
}
}Конфигурация switch-options:
{master:0}
bormoglotx@LEAF-101> show configuration switch-options
vtep-source-interface lo0.0;
route-distinguisher 62.0.0.101:1;
vrf-import VNI-IMPORT;
vrf-target export target:42000:9999;В данной конфигурации мы указываем RD и RT, с которыми будут принимать маршруты от удлаеных VTEP, а так же RT, которая будет навешиваться на маршруты типа 1, сгенерировнные per-ESI.
Содержимое политики, используемой для импорта:
bormoglotx@LEAF-101> show configuration policy-options policy-statement VNI-IMPORT
term DC-DEFAULT {
from {
protocol bgp;
community DC-DEFAULT-SW;
}
then accept;
}
term VNI-16000001 {
from {
protocol bgp;
community VNI16000001;
}
then accept;
}
term VNI-15000001 {
from {
protocol bgp;
community VNI15000001;
}
then accept;
}
then reject;Ну и естественно конфигурация протокола evpn:
{master:0}
bormoglotx@LEAF-101> show configuration protocols evpn
encapsulation vxlan;
extended-vni-list [ 15000001 16000001 ];
multicast-mode ingress-replication;
vni-options {
vni 15000001 {
vrf-target export target:1500:1;
}
vni 16000001 {
vrf-target export target:1600:1;
}
}В этой иерархии мы указываем, какое rt будет соответствовать каждому VNI и какие VNI у нас вообще разрешены.
Далее разрешаем нужный влан в сторону клиента и проверяем работоспособность.




