— А что бы вы со своей стороны могли предложить?
— Да что тут предлагать… А то пишут, пишут… конгресс, немцы какие-то… Голова пухнет. Взять все, да и поделить.
— Так я и думал, — воскликнул Филипп Филиппович, шлепнув ладонью по скатерти, — именно так и полагал.
М. Булгаков, «Собачье сердце»
Про разделение скорости, приоритезацию, работу шейпера и всего остального уже много всего написано и нарисовано. Есть множество статей, мануалов, схем и прочего, в том числе и написанных мной материалов. Но судя по возрастающим потокам писем и сообщений, пересматривая предыдущие материалы, я понял — что часть информации изложена не так подробно как это необходимо, другая часть просто морально устарела и просто путает новичков. На самом деле QOS на микротике не так сложен, как кажется, а кажется он сложным из-за большого количества взаимосвязанных нюансов. Кроме этого можно подчеркнуть, что крайне тяжело освоить данную тему руководствуясь только теорией, только практикой и только прочтением теории и примеров. Основным костылем в этом деле является отсутствие в Mikrotik визуального представления того, что происходит внутри очереди PCQ, а то, что нельзя увидеть и пощупать приходится вообразить. Но воображение у всех развито индивидуально в той или иной степени.
Поэтому я решил написать еще один материал, в котором я смешаю теорию с практикой, визуальными примерами и разобью данный материал на блоки от простого, к сложному. С каждым новым примером я буду добавлять необходимую информацию, и в самом конце вы получите полное представление, как это все работает. Думаю, так будет значительно проще понять основные принципы построения шейпера на микротике.
В данном материале я буду рассматривать только Queue Tree очереди с использованием PCQ. Уж извиняйте, Simple Queues для меня это — несколько не тот уровень возможностей. Так же не будет описан устаревший материал, который применим только для пятых версий ROS, хотя в некоторых моментах я буду на него ссылаться для сравнения.
Начнем с простого примера
Имеем микротик:
- WAN интерфейс с белым адресом (1.1.1.1) и входящей скоростью 32 мегабита в секунду.
- LAN — c подсетью 192.168.0.0/24
Задача нарезать входящую в различных комбинациях (Download) скорость для подсети 192.168.0.0/24. Исходящую скорость (Upload) пока трогать не будем, но отмечу, что ее реализация почти ничем не отличается от реализации входящей скорости.
Для того чтобы что то нарезать на микротике мы должны определится с критериями отбора нужного нам трафика и выделить его. Для этого нам понадобится /ip firewall mangle.
Мангл можно представить в виде своеобразного фильтра, способного отбирать из общего потока пакеты и соединения по определенным критериям и выполнять с ними определенные действия.
Наш единственный критерий известен: нам из общего потока нужны только пакеты, которые идут в подсеть 192.168.0.0/24. В качестве действия с этими пакетами мы выберем — назначение пакету маркировки, впоследствии на основе этой маркировки пакеты можно будет обработать в Queue Tree.
Чтобы правильно промаркировать пакет — нужно знать по каким цепочкам в Mangle он проходит. Для этого нужно знать диаграммы движения пакетов (Packet Flow) причем не абы какие, а именно свежие диаграммы т.к. в шестой версии ROS схема немного изменилась. И естественно, посмотрев на эти диаграммы впервые, у вас на устах ничего кроме матерных слов не будет.
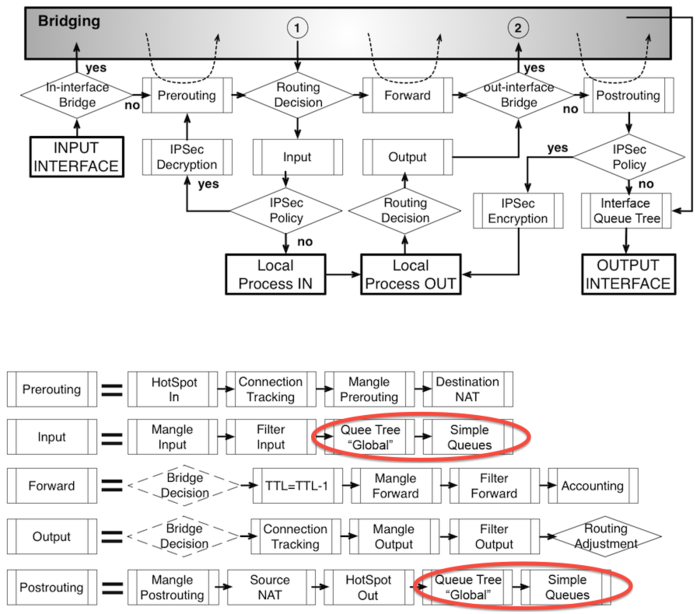
Опять же не все так сложно как кажется, данные диаграммы показывают, как ходит трафик во всех случаях, нам же для работы с шейпером понадобится лишь малая их часть.
Исходя из данной диаграммы, можно понять, что интересующий нас трафик идет по пути:
Input Interface > PREROUTING ->FORWARD ->POSTROUTING -> Output Interface
Схема при включенном NAT будет чуть пожирнее:
Input Interface > PREROUTING > DST-NAT >FORWARD > POSTROUTING > SRC-NAT > Output Interface
Какую из цепочек выбрать?
В пятых версиях ROS кроме того где находится NAT, нужно было еще знать где находится обработка очередей global-in, global-out и global-total. В шестой версии стало все проще, т.к. вышеуказанные обработки упразднили и заменили одним global. И находится этот global в самом конце POSTROUTING, после него обрабатываются очереди SimleQueue и пакет отпускается на волю. Исходя из этого — нам неважно, где он теперь, т.к. все обработки по маркировке производятся до него.
А раз так, то единственное ограничение нам создает только NAT и выбор будет зависеть от направления трафика, который мы хотим промаркировать. По этому случаю накидал свою диаграмму:
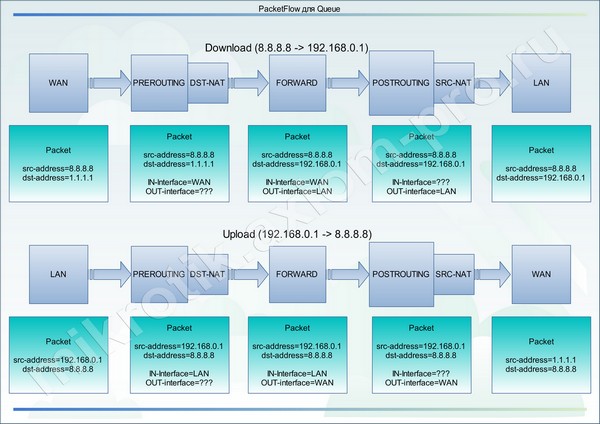
Как видно из диаграммы, для маркировки полученных пакетов, нам нужны цепочки, в которых доступны серые адреса подсети 192.168.0.0/24 (dst-address). А видно их только в FORWARD и POSTROUTING.
Для того чтобы промаркировать Upload пакеты нужны цепочки со второй половины диаграммы, в которых доступны серые адреса подсети 192.168.0.0/24 (src-address). А доступны они во всех трех цепочках PREROUTING, FORWARD, POSTROUTING.
Я рад, что не поленился и написал так много лишних букаф. И все для того, чтобы донести до вас информацию о том, что независимо от направления, которое мы хотим промаркировать, можно выбрать цепочку FORWARD в обоих случаях. Но так нельзя делать в пятых версиях ROS.
С цепочкой определились, теперь нужно определиться с тем, как мы будем помечать пакеты. Сначала пометить соединения, а уже потом в них пометить нужные пакеты? Или просто пометим пакеты и все взлетит?
Как то давно во времена первых версий из шестой линейки, мне написал один хороший человек (за что ему огромное спасибо!), и сказал, что у него в системе интересный глюк. Дал он мне соединение на TeamViewer и показал, как обычная маркировка пакетов помечает на треть (треть! Карл!) пакетов больше, чем маркировка при тех же параметрах но в пределах соединений. Соответственно и скорости в дереве были в норме, а вот на интерфейсах были на треть выше. Ковырялся долго, ничего не нашел. Делал повторую маркировку по тем же критериям вне коннекшена, предварительно отключив дальнейшие передачи уже помеченных пакетов в вышестоящих правилах. Все это с занесением в лог. Нормальные обычные пакеты, почему они не попали в коннекшен так и не понял. Поставил ту же версию себе на тестовый стенд (один WAN, один LAN и все это под двойной NAT) настроил правила и поймал тот же глюк у себя. На протяжении четырех-пяти (уже не помню) версий я ловил данный глюк. Потом тупо сделал нагрузочный тест и понял — не такое уж и великое снижение нагрузки на камень, чтобы использовать маркировку в соединениях. С тех пор, на маркировку пакетов в соединениях — я забил. Как руки дойдут — проверю, а пока маркирую пакеты так.
Ну, с этим закончили. Правило в студию!
Данным правилом мы помечаем все пакеты, у которых dst-address равен адрес листу «LAN» ну и назначаем им packet-mark тоже «LAN».
ip firewall mangle add action=mark-packet chain=forward comment=LAN disabled=no dst-address-list=LAN new-packet-mark=LAN passthrough=yes;
Так же добавим и сам адрес лист:
/ip firewall address-list add address=192.168.0.0/24 disabled=no list=LAN;
На этом маркировка в одном направлении закончена, чтобы промаркировать исходящий трафик, нам нужна копия правила, где dst-address-list=LAN заменен на src-address-list=LAN.
Но как я уже писал, для примера мы возьмем только входящий трафик.
Ловим трафик в Queue Tree
Для того чтобы создать очередь PCQ в данном случае требуется одно правило и профиль в Queue Type. Но я создам два правила, чтобы на одном примере показать как в том, или ином случае ведет себя очередь при установке лимитов.
Родительская очередь
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=30M name=DOWNLOAD parent=global priority=8
Тут стоит прояснить несколько моментов:
- parent=global — В данном параметре можно указать либо «global» либо имя интерфейса. Имя интерфейса тут играет роль определенного фильтра направления трафика и используется в сложных конфигурациях для исключения всех направлений кроме указанного интерфейса и действует только для этой очереди и ее потомков. Всегда указывайте в данном параметре «global» эффект будет тот же, а проблем меньше.
- max-limit=30M — в условии задачи указано что канал у нас выдает 32 метра, но прописывать нужно чуть меньше доступной скорости. В противном случае вы упретесь в шейпер своего провайдера, ваш же просто не будет работать.
- burst-limit=0 burst-threshold=0 burst-time=0s — отключены т.к. их использование мало чего дает при PCQ, но в профиле они имеют достаточную актуальность для использования.
- priority=8 — приоритет очереди, 1 — высший приоритет, 8 — низший приоритет. НЕ РАБОТАЕТ если очередь имеет потомков.
Приоритеты работают только у потомков, причем конкурируют они друг с другом не только в пределах своего родителя, но и с потомками других родителей и только в случае общего дедушки, который лимитирует этим дармоедам скорость. При одинаковых приоритетах они распределят между собой всю доступную дедушкой скорость. При разных — сначала из общей дедушкиной миски едят высокоприоритетные, потом едят те у кого приоритет пониже и то только если что-то осталось, ну или родители развели дедушку на Limit-at. Хотя и родители могут устроить битву титанов среди своих потомков, если у них установлен не только Limit-at, но и Max-limit. Это будет в стиле: «не сжирайте все, у деда есть и другие дети с внуками от первого брака!»
Ну да постебались и хватит! Про лимиты и приоритеты расскажу более наглядно чуть позже.
В общем, мы создали родителя, теперь ему нужен потомок. Но для добавления потомка (конечной очереди) сначала необходимо добавить профиль. Добавляем.
/queue type add kind=pcq name= PCQ_DOWNLOAD_LAN pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000;
- kind=pcq — Указываем что очередь которая использует данный профиль является инициатором подочередей PCQ.
- pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s — Настройки Burst Скоростей, об этом чуть позже.
- pcq-classifier=dst-address — Данный параметр указывает по какому классификатору будут создаваться PCQ очереди. В данном случае по адресу назначения (входящий трафик).
- pcq-dst-address-mask=32 и pcq-src-address-mask=32 — задают количество адресов в одной очереди. (32=одна очередь на один ip адрес).
- pcq-rate=0 — Устанавливает верхний лимит скорости для одной PCQ очереди (в нашем случае для одного ip адреса) Если указан ноль — скорость не ограничена и будет разделена поровну между очередями (ip адресами). В нашем случае 30 мегабит будут разделены поровну между активными очередями (ip адресами).
- pcq-limit=50 — лимит размера одной очереди (для одного ip адреса) Все данные в этой очереди при достижении лимитов задерживаются, все что в нее не влезло — уничтожается.
- pcq-total-limit=2000 — лимит размера всех очередей.
Теперь, когда у нас есть родительская очередь и профиль под потомка, мы добавим самого потомка:
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=LAN packet-mark=LAN parent=DOWNLOAD priority=8 queue=PCQ_DOWNLOAD_LAN;
- packet-mark=LAN — вот тут мы ловим в очередь поток промаркированных в мангле пакетов.
- parent=DOWNLOAD — указали родителя, который ограничил нам скорость.
- queue=PCQ_DOWNLOAD_LAN — ссылаемся на профиль с настройками в Queue Type
Ну, вот и закончили с правилами. Посмотрим на визуальную диаграмму.
Все что происходит наверху, вы уже знаете, далее смешанные промаркированные пакеты в хаотичном порядке, кучей подхватываются очередью потомком. И тут начинается самое интересное.
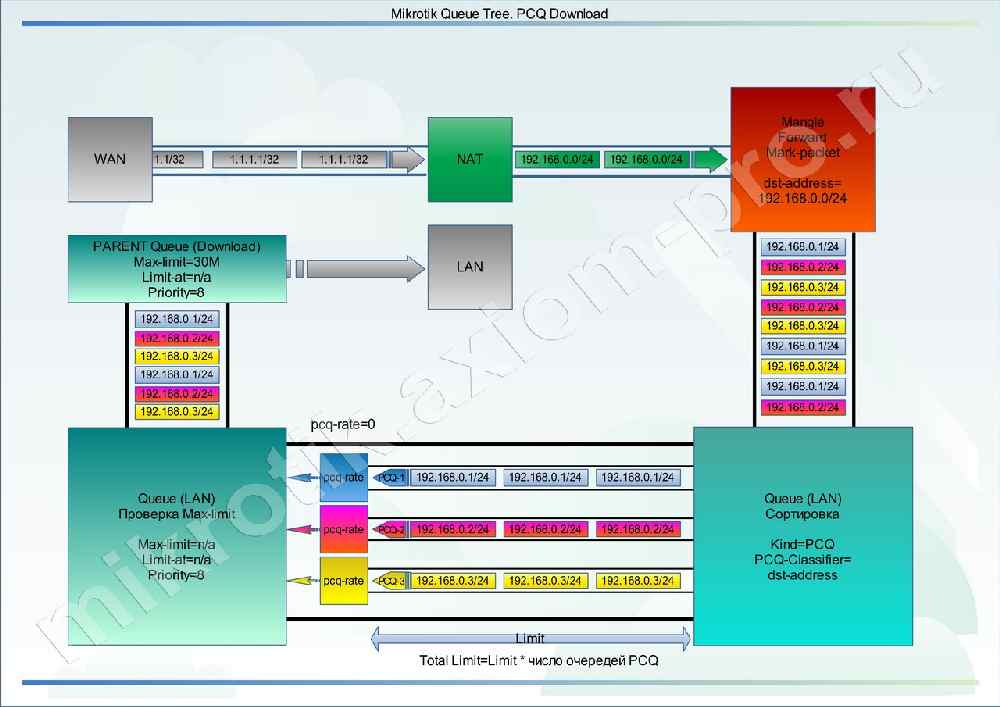
Допустим, у нас сейчас в подсети работают три машины: 192.168.0.1, 192.168.0.2 и 192.168.0.3.
В связи с тем, что потомок привязан к профилю с именем «PCQ_DOWNLOAD_LAN», профиль ему сообщил: что нужно создать под каждый встреченный в промаркированном потоке dst-ip адрес отдельную PCQ очередь.
У нас внутри Queue Tree очереди будет создано три PCQ очереди (потока) с одинаковыми параметрами pcq-rate, pcq-limit и настройками Burst скоростей.
В данном случае очередь сработала как своеобразный сортировщик пакетов. И для каждого пользователя создала индивидуальную очередь.
Каждая очередь проходит через pcq-rate, именно эта штука и задерживает пакеты в индивидуальных очередях.
Далее пакеты смешиваются и поступают во вторую часть Queue Tree очереди c именем «LAN», где проходят проверку на суммарную скорость по Max-Limit, если он есть и исчерпан, то этот Max-limit будет поделен поровну между PCQ-очередями (потоками), задержка производится на уровне pcq-rate, какие-то очереди ускоряются, какие-то притормаживаются. Все что не влезло в pcq-limit — уничтожается.
Но у нас этого параметра в очереди «LAN» не установлено и поэтому трафик ползет вверх к родительской очереди (DOWNLOAD). Там все происходит по аналогии, проверяется Max-Limit и если он достигнут — родительская очередь пинает pcq-rate на закрытие дышла. Скорости потоков выравниваются, и все приходит в норму.
Представим на секунду, что мы не установили Max-Limit в родительской очереди. Так вот, если нигде по пути трафика при pcq-rate=0 не было обнаружено значения Max-Limit, то и вся очередь не будет работать, весь трафик пройдет сквозь шейпер без задержек, т.к. некому сообщить pcq-rate что канал не резиновый.
Многих мучает вопрос, если в данном случае pcq-rate=0, пользователей три, двое спят, а один качает. Он выжирает все 30 мегабит? — Да!
А что будет, если проснется еще один и тоже начнет качать? — Будет произведено перестроение и выравнивание скоростей. 30 мегабит они поделят поровну. Единственный нюанс — на это требуется время, второй пользователь будет немного медленнее набирать скорость, чем обычно.
Суть механизма заключается в задержке и уничтожении пакетов, которые не влезли в лимит. Протокол TCP устроен таким образом, что в рамках соединения — сервер который отправляет данные клиенту, проверяет как они дошли до него, если у пакетов выросла задержка или пакет потерялся (нарушение последовательности) сервер снижает скорость отправки чтобы увеличить стабильность.
pcq-limit и pcq-total-limit задаются экспериментально, чем больше лимит — тем больше задержка и больше занято оперативной памяти роутера. Чем меньше лимит — тем больше пакетов будет уничтожено.
Что будет, если задать pcq-rate=5M?
Каждый пользователь получит не более 5 мегабит. 3 активных пользователя * 5 мегабит =15 мегабит.
Три активных пользователя, все качают по полной, pcq-rate=11M?
Скорость упрется в Max-limit родительской очереди (30M) и данная скорость будет поделена между пользователями равномерно по 10 мегабит. Если один из них уйдет с закачки или снизит свою скорость минимум до 8 мегабит, двое остальных разгонятся до 11 мегабит.
Я очень надеюсь, что по данному примеру все понятно, если непонятно — прочтите еще раз и еще раз, далее будет сложнее.
Burst
Технология Burst предназначена для подачи увеличенной скорости при назначенном лимите на короткое время. Использовать данную функцию целесообразно на небольших по скорости тарифах, для ускорения веб-серфинга или быстрой подгрузки данных в приложения. Данная функция работает только в случае если pcq-rate не равен нулю. Не буду до посинения грузить вас графиками и формулами расчета, лучше накидаю пример.
- Pcq-rate=2M
- pcq-burst-rate=4M
- pcq-burst-threshold=1M
- pcq-burst-time=10s
Максимальная скорость работы пользователя равна 2 мегабитам. Если скорость его работы в данный момент менее 1 мегабита (pcq-burst-threshold), ему станет доступна скорость в 4 мегабита (pcq-burst-rate) на 10 секунд (на практике меньше) это pcq-burst-time. Счетчик начинает тикать с того момента как будет превышен порог в 1 мегабит (pcq-burst-threshold), по истечении времени скорость упадет до pcq-rate, чтобы Burst снова стал доступен — скорость пользователя должна упасть ниже 1 мегабита и находится там не менее 10 секунд (pcq-burst-time).
Понятно, что это очень грубое объяснение, на самом деле время доступности burst рассчитывается по непростому алгоритму — время делится на 16 отрезков и учитывая почти все переменные скорости и лимитов рассчитывается время действия. Данная функция потребляет значительное количество ресурсов, используйте ее с умом.
Для справки: При внесении любых изменений, в любую очередь и в любом ее проявлении (Tree или Simple) — все счетчики обнуляются в т.ч. и счетчики Burst. Если вы используете скрипты для автоматической коррекции значений Max-Limit типа QOSEvxController — будьте готовы отказаться от Burst или использовать циклы проверки очередей в QOSEvxController не так часто.
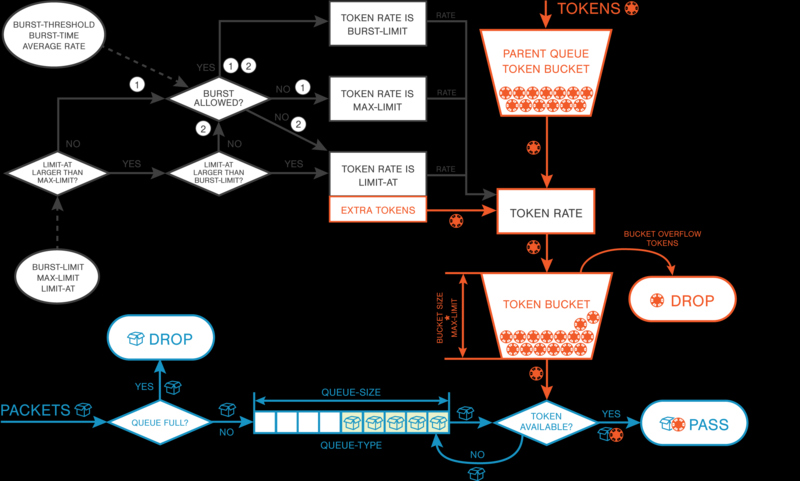
Ведро с болтами (Bucket)
Так же с недавнего времени в шестой версии ROS для очередей появился новый параметр bucket-size (размер ведра). Данный параметр может быть изменен в пределах от 0.1 до 10 и используется для задания емкости ведра с токенами. Емкость ведра рассчитывается по форумуле:
Емкость в МЕГАБАЙТАХ=bucket-size * max-limit
Над каждой очередью нависает ведро с гомном токенами, пока трафик в данной очереди не превышает лимит (max-limit) токены накапливаются в данном ведре. При переполнении ведра токен падающий в полное ведро уничтожается.
На что тратятся токены.
/queue tree add name=download parent=global packet-mark=PC1-traffic max-limit=10M bucket-size=10;
В данном примере, емкость ведра будет равна: (max-limit=10M) * (bucket-size=10) = 100 мегаБАЙТАМ
Если пользователь или пользователи потока пакетов с маркировкой «PC1-traffic» до недавнего времени ничего не качали на полной скорости — ведро с токенами в данной очереди будет полным, а это целых сто мегабайт трафика. И вот решили они дружно, что то качнуть, так вот, первых 100 мегабайт трафика они получат без ограничения скорости по max-limit, когда 100 мегабайт будет скачано очередь начнет ограничивать скорость согласно заданному max-limit=10M.
Кроме этого, если у очереди есть родитель с более жирным max-limit, то после того как потомок выжрет все свои токены, из своего ведра, он начнет забирать токены у родительской очереди.
Для чего это нужно?
Bucket-size это как своеобразный Burst, только не по скорости а по объему трафика. Применение его совместно с PCQ очередями даст лишь сомнительную пользу. В одиночных сеялках типа pfifo, red и sfq может быть крайне полезен. Для PCQ очередей — единственное, что приходит в голову, это то, что мы лимитируем родительскими очередями скорость, которая чуть ниже реальной скорости канала. Грамотное использование данной функции может кратковременно более полно эксплуатировать всю доступную скорость канала и сглаживать пики активности пользователей.
Более подробная диаграмма работы ведра:
Эквиваленты маркировки трафика
В данном примере я указал, что у нас одна подсеть (192.168.0.0/24) с тремя пользователями (192.168.0.1, 192.168.0.2, 192.168.0.3). Мы пометили трафик к данным адресам одним правилом в mangle и одним адрес-листом. На всякий случай скажу, что для mangle нет разницы, как мы ему скормим адреса для пометки — обработаны они будут одинаково.
Подсеть целиком:
/ip firewall address-list add address=192.168.0.0/24 disabled=no list=LAN;
Диапазон адресов:
/ip firewall address-list add address=192.168.0.1-192.168.0.3 disabled=no list=LAN;
Отдельные адреса:
/ip firewall address-list add address=192.168.0.1 disabled=no list=LAN;
/ip firewall address-list add address=192.168.0.2 disabled=no list=LAN;
/ip firewall address-list add address=192.168.0.3 disabled=no list=LAN;
Аналогично обстоит дело и с PCQ очередями. PCQ очередь без проблем разбирает один поток пакетов, помеченный одним правилом, состоящий из адресов разных подсетей на подочереди.
Допустим, что мы подмешали еще трех пользователей из другой подсети (192.168.1.1, 192.168.1.2, 192.168.1.3). Просто добавив нужные записи в адрес-лист. Тогда получим такую картину:
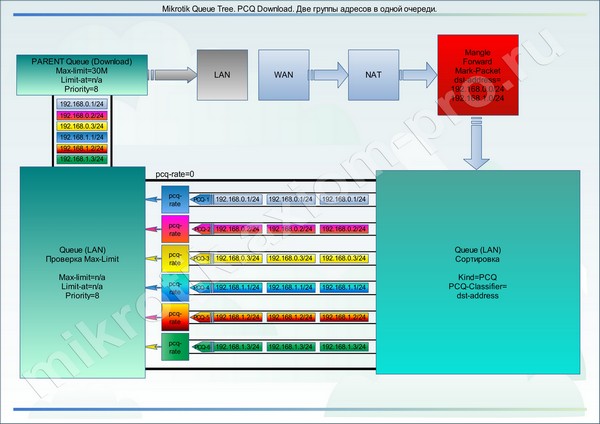
Исходя из всего вышеперечисленного, можно сделать вывод, что оперируем мы не подсетями, а группами ip адресов, которые создаем с помощью адрес-листов.
В данном случае нет смысла раздельно маркировать трафик, делать два профиля и две очереди. Такой подход необходим только в следующих случаях:
- Когда требуется задать индивидуальный Max-Limit для выбранной группы адресов.
- Когда требуется различный приоритет для групп адресов или типа трафика.
- Когда требуется реализация различных тарифных планов для группы адресов. (pcq-rate)
- И во всех возможных комбинациях вышеперечисленных случаев.
А вот пример того, как делать не надо:
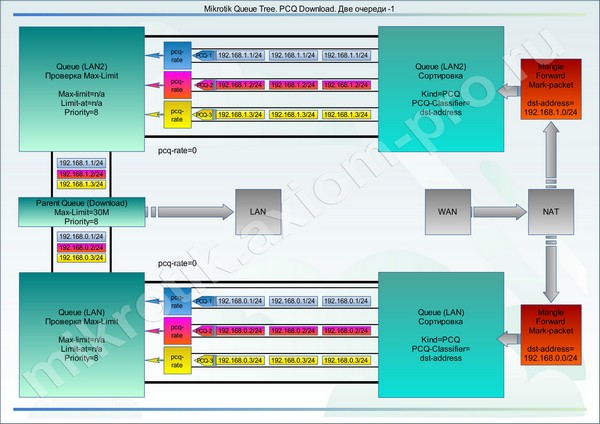 Полный листинг примера:
Полный листинг примера:
/ip firewall mangle add action=mark-packet chain=forward comment=LAN disabled=no dst-address-list=LAN new-packet-mark=LAN passthrough=yes;
/ip firewall address-list add address=192.168.0.0/24 disabled=no list=LAN;
/queue type add kind=pcq name= PCQ_DOWNLOAD_LAN pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000;
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=30M name=DOWNLOAD parent=global priority=8;
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=LAN packet-mark=LAN parent=DOWNLOAD priority=8 queue=PCQ_DOWNLOAD_LAN;
Другие части:
- Mikrotik QOS в распределенных системах или умные шейперы. Часть 1.
- Mikrotik QOS в распределенных системах или умные шейперы. Часть 2.
- Mikrotik QOS в распределенных системах или умные шейперы. Часть 3.
- Mikrotik QOS в распределенных системах или умные шейперы. Часть 4.
© Григорьев Дмитрий https://habrahabr.ru/post/307214/




